14 min to read
자료구조(12) - 힙의 ADT와 구현
힙의 ADT 작성 및 구현

🔚 짧게 하는 복습
✅ 1. CBT와 스택 구조의 공통점을 이해하고 ADT를 구현할 수 있다.
✅ 2. BST의 제거 알고리즘을 이해한다.
✅ 3. BST의 ADT를 구현할 수 있다.
혹시 기억이 안 난다면, 다시 돌아가자
저번 시간까지 완전 이진 트리(CBT)와 이진 탐색 트리(BST)에 대해 다루었다.
CBT는 구현할 때 스택의 동작과 거의 비슷하다는 성질을 이용했다.
그리고 BST는 구현 및 디테일이 굉장히 까다로웠는데, 특히 제거가 굉장히 어려웠다.
간단히 복기하자면 리프 노드면 바로 해제, 아니라면 리프 노드의 값 중 가장 가까운 값을 옮기고 지운다는 점이 중요했다.
또한, treePointer, int의 return을 이용한 재귀 함수 등 여러 구현 팁을 얻을 수 있었다.
BST는 말 그대로 조회(Search)가 핵심인 트리로, 정렬되어있다는 특징을 이용해서 재귀 구조로 모든 기능을 구현했다.
이번 강의에서 다룰 트리는 힙이다.
힙의 주된 기능은 최댓값 혹은 최솟값을 찾아내는 것이다.
안에 어떤 원소가 얼마나 들어있는지 관계없이, 최댓값 그리고 최솟값을 찾아내는 것이다.
힙이란?
힙은 최댓값을 찾느냐, 최솟값을 찾느냐에 따라 Max 힙과 Min 힙으로 나눌 수 있다.
그 중 Max 힙은 CBT의 응용 트리로, 각 노드의 값이 모든 자식 노드들의 값보다 크거나 같은 트리를 말한다.
그리고 반대로, Min 힙은 각 노드의 값이 모든 자식 노드들의 값보다 작거나 같은 트리를 말한다.
예를 들어, 아래와 같은 트리는 Max 힙
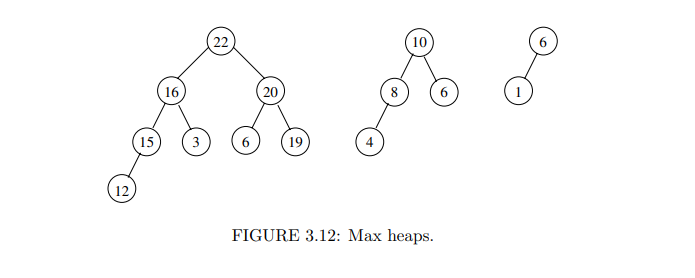
또, 아래와 같은 트리들은 Min 힙이다.
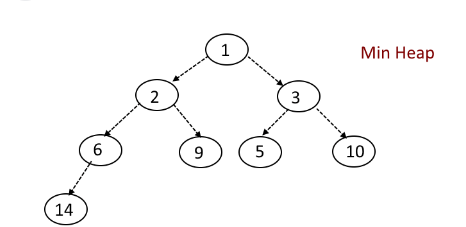
즉, BST가 좌우로 정렬된 트리라면 힙은 상하로 정렬된 트리인 것이다.
(하지만 BST는 Inorder traversal을 하면 정렬된 채로 나오지만, 힙은 Level order traversal을 해도 정렬되지 않는다.)
오늘은 Max 힙의 ADT와 구현에 대해서만 다루어보겠다. (Min 힙은 과제로 넘기겠다.)
Max 힙 ADT
역시나 ADT는 요구에 맞게 작성되는 것이기에, 절대적인 것이 아니라 필요에 맞게 수정할 수 있다.
Max 힙의 구현
Max 힙도 CBT가 기반이기에, 트리가 아니라 배열(정적, 동적 둘 다 가능) 혹은 연결리스트로 구현이 가능하다.
구현의 편의를 위해서는 배열로 하겠다. (연결리스트는 과제로 넘긴다.)
배열, 연결리스트 어떤 구조를 이용하더라도, 힙의 핵심 기능은 heapify이다.
heapify란 어떠한 원소를 삽입/삭제한 후 정렬되지 않은 트리를 정렬된 힙의 구조로 돌리는 것을 말한다.
우선 삽입되었을 때 일어나는 Insertion heapify에 대해 알아보자.
<img src = “https://res.cloudinary.com/dtloik0ts/image/upload/v1705907531/Insertion-In-Max-Heap_alpxjv.png>
-
우선 맨 마지막에 원소를 삽입한다.
-
부모 노드가 있고, 부모 노드의 값보다 삽입된 원소가 크면, 둘의 자리를 바꾼다. (힙fiy)
-
삽입된 원소가 root로 가거나, 부모 노드보다 작을 때까지 이 작업을 반복한다.
그럼 반대로 Deleteion heapify에 대해서도 알아보자.

-
마지막에 삽입된 원소를 루트 노드의 값으로 복사한다.
-
그 후 자식 노드가 있고, 자식 노드가 루트 노드의 값보다 크다면 둘의 자리를 바꾼다. (만약 두 자식 노드 모두 루트보다 크다면 더 큰 자식 노드의 값을 루트로 올린다.)
-
삽입된 원소가 리프 노드로 가거나, 자식 노드보다 클 때까지 반복한다.
이제 코드를 직접 짜보자.
사실상, CBT의 코드에 Heapify만 추가해주면 끝이다!
#include <stdio.h>
#include <stdlib.h>
/*
자료 : 정수
기능1 삽입 : 원소를 Max 힙에 삽입한다.
기능2 삭제 : 원소를 Max 힙에서 삭제한다.
기능3 조회 : Max 힙에서 최대값을 조회한다.
기능4 순회 : Heap의 모든 원소를 level-order로 순회한다.
*/
typedef int* Heap; //typedef를 통한 변환
int left_child(const int index) {
return 2 * index + 1;
}
int right_child(const int index) {
return 2 * index + 2;
}
int parent(const int index) {
return (index - 1) / 2;
}
//+ empty한지 확인
int is_empty(const int num_of_nodes) {
if (num_of_nodes == 0) {
return 1; //비었으면 참
}
else {
return 0;//아니면 거짓
}
}
void swap(int* x, int* y) {
int temp = *x;
*x = *y;
*y = temp;
return; // swap용 함수
}
//+ leaf node인지 확인
int is_leaf(const int index, const int num_of_nodes) {
if (left_child(index) > num_of_nodes - 1) {
// 마지막 노드의 index는 num_of_nodes -1이니까
return 1;
}
else {
return 0;
}
}
//+ root node인지 확인
int is_root(const int index) {
if (index == 0) {
return 1;
}
else {
return 0;
}
}
// +) 핵심 기능, insertion Heapify
int insertion_heapify(Heap st, const int index) {
if (is_root(index) || st[index] < st[parent(index)]) {
return 1; // 탈출 조건 및 성공하면 1 반환
}
else {
swap(&st[index], &st[parent(index)]);
return insertion_heapify(st, parent(index));
}
return -1;// 실패하면 -1 반환
}
//기능1 삽입
int insert(Heap* st, const int value, int* num_of_nodes) {
if (is_empty(*num_of_nodes)) {
*st = (Heap)malloc(sizeof(int) * (*num_of_nodes + 1));
}//원소가 없으면 할당
else {
Heap new_st = (Heap)realloc(*st, sizeof(int) * (*num_of_nodes + 1));
*st = new_st;
}//재할당
(*st)[*num_of_nodes] = value;
// 이중 포인터를 이용한 배열 접근을 이렇게 쓸 수도 있다.
printf("%d is pushed into Heap!\n\n", value);
*num_of_nodes += 1;
//대입
//num_of_nodes 증가
insertion_heapify(*st, *num_of_nodes - 1);
// 마지막 노드의 인덱스는 num_of_nodes -1
return 0;
}
// +) 핵심 기능, deletion_heapify
int deletion_heapify(Heap st, const int index, const int num_of_nodes) {
if (is_leaf(index, num_of_nodes)) {
// 탈출 조건1 : 자식이 없을 때
return 1;
}
else if (right_child(index) > num_of_nodes - 1) {
//자식이 하나 있을 때
int l_index = left_child(index);
if (st[index] >= st[l_index]) {
// 탈출 조건2 : 왼쪽 자식보다 크거나 같을 때
return 1;
}
else {
swap(&st[index], &st[l_index]);
return deletion_heapify(st, l_index, num_of_nodes);
}
}
else {
// 자식이 둘 다 있을 때
int l_index = left_child(index);
int r_index = right_child(index);
if (st[index] >= st[l_index] && st[index] >= st[r_index]) {
// 탈출 조건3 : 두 자식보다 크거나 같을 때
return 1;
}
else if (st[index] >= st[l_index] && st[index] < st[r_index]) {
// 오른쪽 자식이 더 크면
swap(&st[index], &st[l_index]);
return deletion_heapify(st, l_index, num_of_nodes);
}
else if (st[index] >= st[r_index] && st[index] < st[l_index]) {
// 왼쪽 자식이 더 크면
swap(&st[index], &st[r_index]);
return deletion_heapify(st, r_index, num_of_nodes);
}
else {
// 두 자식 모두 다 부모보다 크면
if (st[l_index] > st[r_index]) {
// 왼쪽 자식이 오른쪽 자식보다 크면
swap(&st[index], &st[l_index]);
return deletion_heapify(st, l_index, num_of_nodes);
}
else {
// 오른쪽 자식이 왼쪽 자식보다 크면
swap(&st[index], &st[r_index]);
return deletion_heapify(st, r_index, num_of_nodes);
}
}
}
return -1;// 실패하면 -1 반환
}
//기능2 제거
int Delete(Heap* st, int* num_of_nodes) {
if (is_empty(*num_of_nodes)) {
printf("Heap is empty!\n\n");
return -1;
}//원소가 없으면 오류
int ret = **st;// ret값을 미리 저장(재할당을 위해)
(*st)[0] = (*st)[*num_of_nodes - 1];
// 루트에 마지막 값을 대입한다.
// 이중 포인터를 이용한 배열 접근을 이렇게 쓸 수도 있다.
*num_of_nodes -= 1;// num_of_nodes 감소
deletion_heapify(*st, 0, *num_of_nodes);
if (*num_of_nodes == 0) {
*st = NULL;
}//비었으면 NULL
else {
Heap new_st = (Heap)realloc(*st, sizeof(int) * (*num_of_nodes));
*st = new_st;
}//아니면 재할당
return ret;// Delete한 원소 리턴
}
//기능3 조회
int search(Heap st, const int num_of_nodes) {
if (is_empty(num_of_nodes)) {
printf("Heap is empty!\n\n");
return -1;
}//원소가 없으면 오류
return st[0];
}
//기능4 순회(Level_order_traversal)
int level_order_traversal(Heap st, const int num_of_nodes) {
if (is_empty(num_of_nodes)) {
printf("Heap is empty!\n\n");
return -1;
}//원소가 없으면 오류
for (int i = 0; i < num_of_nodes; i++) {
printf("%d ", st[i]);
}
printf("\n\n");
return 0;
}
int main(void) {
Heap st = NULL; // 동적 배열을 통한 스택 구현
int num_of_nodes = 0;
/*
배열 구현에서 cur_size 역할, 즉 스택에 얼마나 많은 원소가 있는지를 나타냄
또한, 가장 최근에 입력된 원소의 인덱스 값이기도 함.
*/
insert(&st, 1, &num_of_nodes);
insert(&st, 3, &num_of_nodes);
insert(&st, 4, &num_of_nodes);
level_order_traversal(st, num_of_nodes); // 4 3 1
insert(&st, 5, &num_of_nodes);
level_order_traversal(st, num_of_nodes); // 5 4 1 3
insert(&st, 2, &num_of_nodes);
level_order_traversal(st, num_of_nodes); // 5 4 1 3 2
Delete(&st, &num_of_nodes);
level_order_traversal(st, num_of_nodes); // 4 3 1 2
Delete(&st, &num_of_nodes);
level_order_traversal(st, num_of_nodes); // 3 2 1
Delete(&st, &num_of_nodes);
level_order_traversal(st, num_of_nodes); // 2 1
Delete(&st, &num_of_nodes);
level_order_traversal(st, num_of_nodes); // 1
free(st);
}
위를 참고하면, 얼마나 앞의 내용 복습이 철저해야 하는지 알 수 있다.
동적 배열을 기반으로 해서 스택을 만들고, 스택을 기반으로 CBT를 만들며, CBT를 기반으로 Max 힙을 구현해낸 모습이다.
이 코드에서는 최대한 반복되는 내용을 함수로 만들어서 빼는 스킬을 배울 수 있었다.
또한, 이중 포인터를 이용한 간접참조를 (*st)[index]로 하는 방법에 대해서도 간접적으로 다루었다.
결과창
1 is pushed into Heap!
3 is pushed into Heap!
4 is pushed into Heap!
4 1 3
5 is pushed into Heap!
5 4 3 1
2 is pushed into Heap!
5 4 3 1 2
4 2 3 1
3 2 1
2 1
1
우선순위 큐란?
우선순위 큐(Priority Queue)는 각 원소에 우선순위를 부여하고, 우선순위 가장 높은 값을 다루는 자료구조이다.
여러 가지 방법으로 구현할 수 있는데, 정수 데이터의 크기를 우선순위로 한다면 Max 힙으로 많이 구현한다.
물론 우리가 배운 BST, 배열 등으로도 다룰 수 있는데 이는 과제로 남기겠다.
📖 오늘의 핵심(다 알기 전까지는 넘어가지 말자❗)
✅ 1. 힙의 ADT를 구현할 수 있다.
✅ 2. 우선순위 큐가 무엇인지 이해한다.
⚠️ 이중 포인터를 이용한 배열은 *(arr)[index]로 참조할 수 있다.
💣 과제,
-
Min 힙을 구현해보자(난이도 中)
-
연결리스트를 통한 Min 힙을 구현해보자(난이도 中)
-
BST를 통한 우선순위 큐를 구현해보자(난이도 中)
-
배열을 통한 우선순위 큐를 구현해보자(난이도 中) (버블 정렬을 검색해보자)
🔜 더 공부해보기,




Comments