14 min to read
자료구조(21) - 맵(딕셔너리)
이진 검색 트리와 해시 테이블을 이용한 맵(딕셔너리) 구현

🔚 짧게 하는 복습
✅ 1. 체이닝을 통해 충돌 관리를 할 수 있다.
✅ 2. 개방 주소법의 각 탐사 방법을 안다.
✅ 3. 각 탐사 방법의 장단점을 안다.
✅ 4. 체이닝과 개방 주소법을 구현할 수 있다.
✅ 5. 적재율과 좋은 해시 함수의 조건을 안다.
혹시 기억이 안 난다면, 다시 돌아가자
이제 어느덧 자료구조 마지막 강의이다.
저번 강의에서 다룬 것은 집합이었다. 한 원소가 어느 집합에 있는지 없는지 확인하는 것이었다.
반면에 이번 강의에서 다룰 것은 어떠한 두 자료가 쌍으로서 의미가 있을 때를 다룰 것이다.
대표적으로는 아이디와 비밀번호이다.
아이디와 비밀번호는 있는지 없는지만 확인하면 안 된다.
그 아이디와 비밀번호가 있는 건 기본이고, 둘이 pair가 맞는지도 확인해야 하기 때문이다.
새로운 자료구조의 등장이 필요하고, 우리는 새로운 자료구조 맵(딕셔너리)를 배울 것이다.
맵(딕셔너리)이란?
영어로는 Map이라고 하던데, 한국어로는 사전이라는 용어를 쓴다고 하길래 어색해서 그냥 원어 그대로 사용하기로 했다.
맵 또는 딕셔너리는 키와 값을 쌍으로 저장하고, 그 키를 통해 값을 다루는 자료구조이다.
근데 이 설명 굉장히 익숙하지 않은가…? 키…? 값…?
그렇다. 집합에서 다루었던 내용과 굉장히 비슷하다.
집합은 원래 값을 키라고 하고, 키의 해시값을 구해서 (해시값, 키)의 쌍으로 다루었다.
이는 해시 테이블이나 BST를 통해 값의 존재에 집중하기 때문이다.
하지만 맵에서는 다루는 값이 2개인데, 인덱스로 사용할 값을 키(key), 저장할 값은 값(value)이라고 한다.
물론 키는 해시 함수를 통해 해시값으로 바꾸고, 다룰 때는 (키를 통한 해시값, 값(value))으로 다룬다.
이는 해시 테이블이나 BST를 통해 두 값의 매핑에 집중하기 때문이다.
참고로 키를 통해 해싱하기 때문에, 값(value)은 중복될 수 있지만 키는 중복이 될 수 없다는 특징도 있다.
아래의 그림을 보면 더 쉽게 오늘 자료구조 구현을 이해할 수 있다.
첫 번째는 집합의 자료구조를 도식화한 것이다.
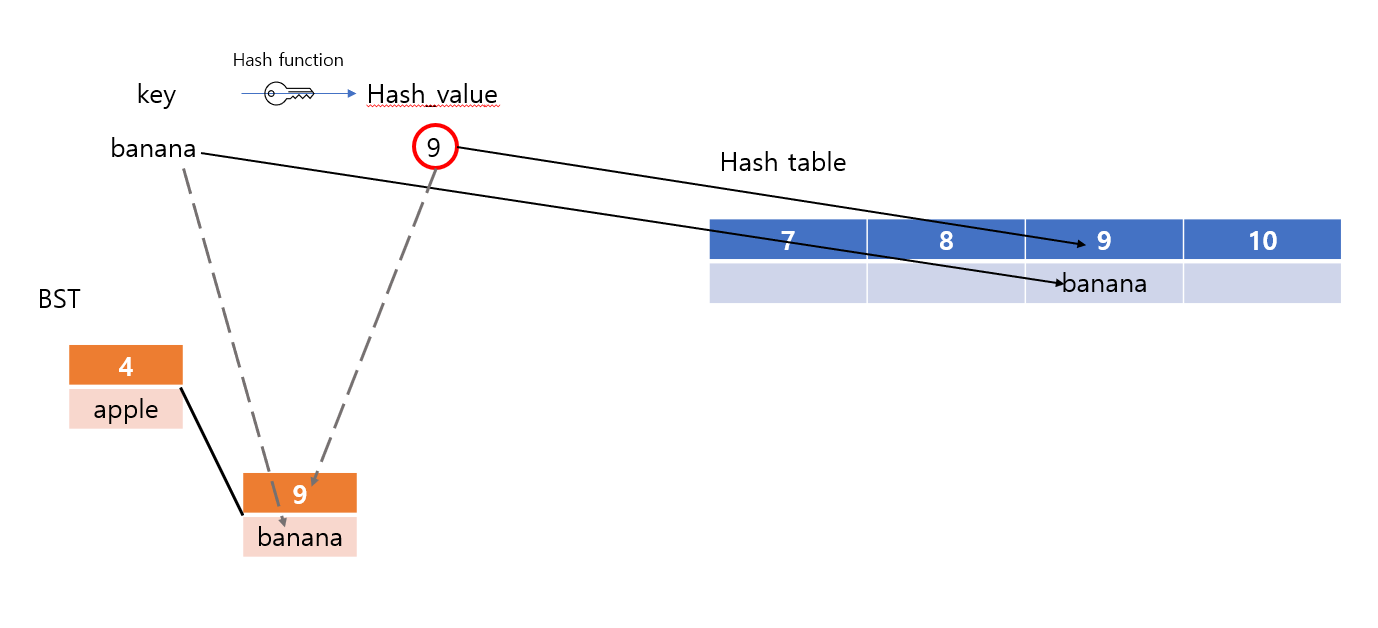
보면 해시값, 원래 값(키)을 BST든 해시 테이블이든 이용해서 집합에 저장한다.
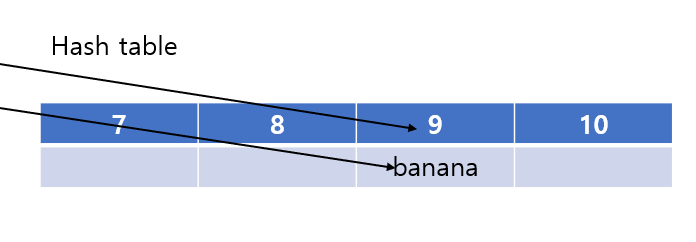
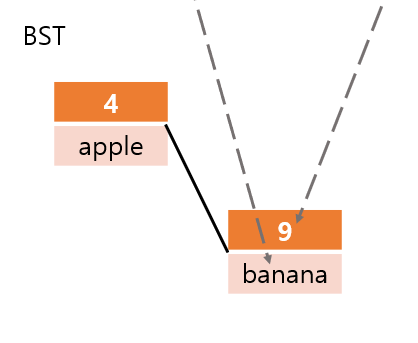
중요한 점은 해시값을 이용해서 키를 저장했다는 점이다.
반면에, 맵의 자료구조는 아래와 같이 도식화된다.
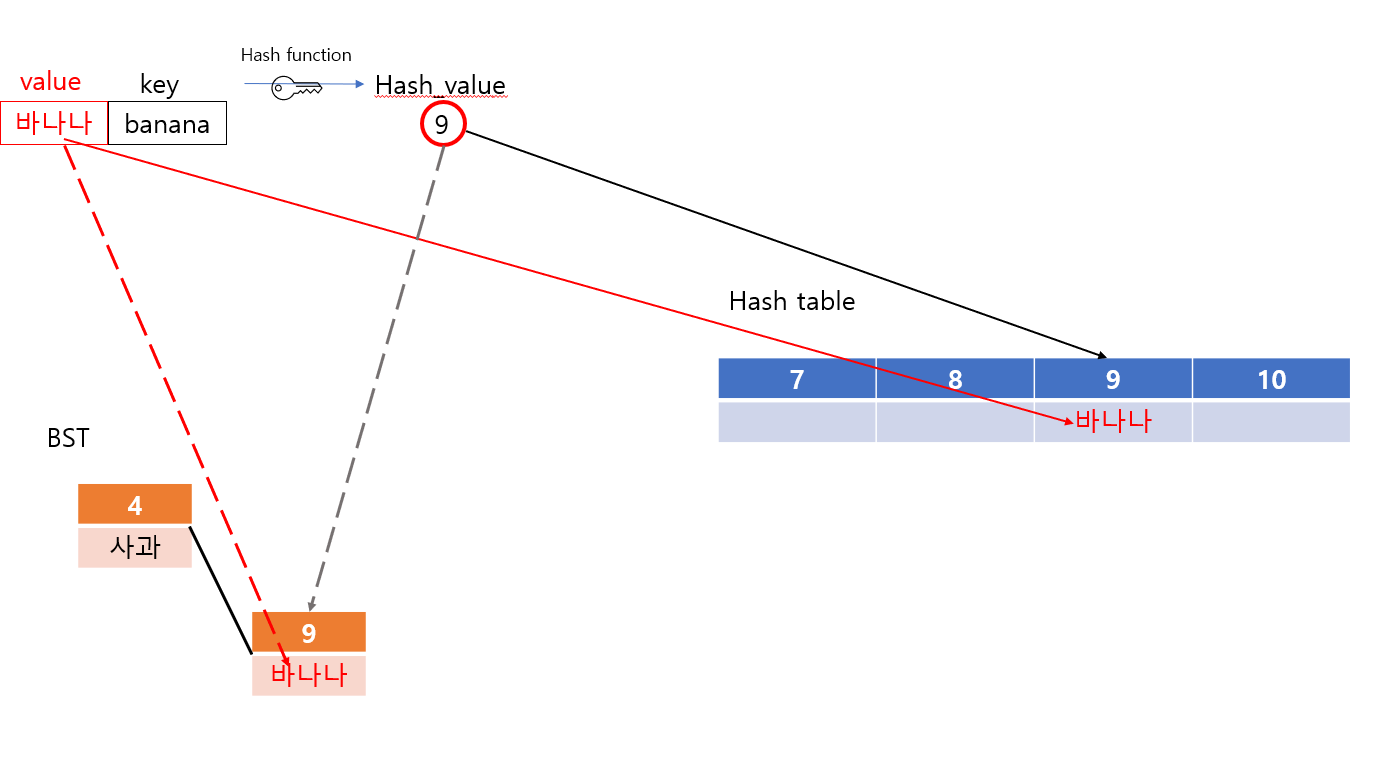
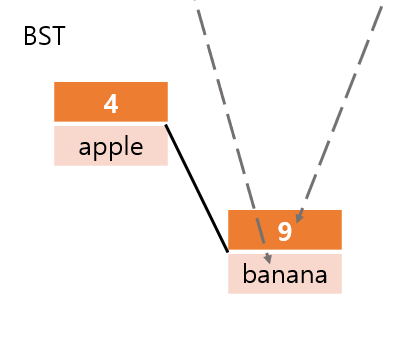
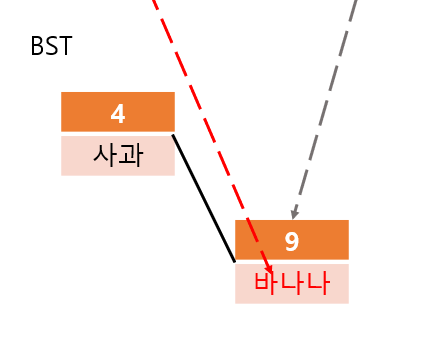
키를 해시값으로 변환하고 인덱스로 사용하는 것까지 같다.
하지만 마지막에 저장하는 것은 키와 대응되는 값(value)이다.
특별히 더 설명할만한 사항이 없다. 바로 ADT와 구현을 들어가 보자.
설명이 적은 만큼 BST와 해시 테이블로 둘 다 구현해보겠다.
맵(딕셔너리)의 ADT
BST를 이용한 맵의 구현
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include<stdlib.h>
#include<string.h>
/*
자료 : { "banana : 바나나", "apple : 사과", "pineapple : 파인애플", "orange : 오랜지"}
기능1 추가 : 맵에 키, 값 쌍을 추가한다
기능2 삭제 : 맵에 키, 값 쌍을 제거한다
기능3 조회 : 맵에서 키를 통해 저장된 값을 확인한다.
*/
typedef struct Node* treePointer;
typedef struct Node {
int key; // 키를 통한 해쉬 값
char data[10]; // 원래 값(value)
treePointer left_child; // 첫째 자식 노드를 가리키는 포인터
treePointer right_child; // 둘째 자식 노드를 가리키는 포인터
} node; // 노드
// + 노드를 만드는 함수
treePointer make_node(const int key, char* data) {
treePointer new_node = (treePointer)malloc(sizeof(node));
new_node->key = key;
strcpy(new_node->data, data);
new_node->left_child = NULL;
new_node->right_child = NULL;
return new_node;
}
//기능1 삽입 : 원소를 BST에 삽입한다.
treePointer insert(treePointer root, char* key, char* data) {
//void나 int 대신 treePointer를 쓰면 코드를 간결하게 작성할 수 있다.
int hash_value = hash(key);
if (root == NULL) return make_node(hash_value, data);
// 삽입될 위치를 찾을 때까지 따라가다가, leaf에서 삽입
if (hash_value < root->key)
root->left_child = insert(root->left_child, key, data);
else if (hash_value > root->key)
root->right_child = insert(root->right_child, key, data);
return root;
}
treePointer findMin(treePointer root) {
while (root->left_child != NULL)
root = root->left_child;
return root;
}// Delete를 위한 함수, 서브트리의 최소값을 찾음
/*
기능2 삭제 : 원소를 BST에서 삭제한다.
1. 자식 노드가 없는 경우: 해당 노드를 삭제
2. 자식 노드가 하나인 경우: 해당 노드를 삭제하고,
자식 노드를 삭제된 노드의 부모 노드에 연결한다.
3. 자식 노드가 둘인 경우: 삭제할 노드를 삭제하고,
그 자리에 삭제된 노드보다 큰 값 중 가장 작은 노드, 또는
삭제된 노드보다 작은 값 중 가장 큰 노드를 가져와야한다.
*/
treePointer Delete(treePointer root, char* key) {
//void나 int 대신 treePointer를 쓰면 코드를 간결하게 작성할 수 있다.
int hash_value = hash(key);
if (root == NULL) return root;
// 삭제할 노드 찾기
if (hash_value < root->key)
root->left_child = Delete(root->left_child, key);
else if (hash_value > root->key)
root->right_child = Delete(root->right_child, key);
else {
// 삭제할 노드를 찾았을 때
if (root->left_child == NULL) {
// 삭제할 노드가 자식이 0개 혹은 1개인 경우
treePointer temp = root->right_child;
// Null과 반대 방향 자식을 가리키기를 동시 처리.
free(root);
return temp;
}
else if (root->right_child == NULL) {
// 삭제할 노드가 1개의 자식을 가지는 경우
treePointer temp = root->left_child;
free(root);
return temp;
}
// 삭제할 노드가 두 개의 자식을 가지는 경우
treePointer temp = findMin(root->right_child);
root->key = temp->key;
root->right_child = Delete(root->right_child, temp->key);
}
return root;
}
// BST의 성질을 이용한 조회의 핵심 기능
char* rec_search(treePointer root, char* key) {
if (root == NULL) {
return ""; // 찾지 못한 경우 0 반환
}
int hash_value = hash(key);
if (hash_value < root->key) {
return rec_search(root->left_child, key);
// key가 루트의 값보다 작으면 왼쪽
}
else if (hash_value > root->key) {
return rec_search(root->right_child, key);
// 아니면 오른쪽 이동
}
else {
return root->data;
// 찾은 경우 1 반환
}
}
// 기능3 조회 : 원소를 BST에서 조회한다.
void search(treePointer root, char* key) {
char data[10];
strcpy(data, rec_search(root, key));
if (strcmp(data, "")) {
printf("There is %s, %s in BST\n\n", key, data);
}
else {
printf("There is no %s in BST\n\n", key);
}
}
int hash(char* str) {
int length = strlen(str);
int ret = 0;
for (int i = 0; i < length; i++) {
ret += str[i];
}
return ret;
}
int main(void) {
treePointer root = make_node(hash("banana"), "바나나");
insert(root, "apple", "사과");
insert(root, "pineapple", "파인애플");
insert(root, "orange", "오랜지");
search(root, "banana");
search(root, "apple");
search(root, "pineapple");
search(root, "orange");
Delete(root, "apple");
search(root, "apple");
}
결과창
There is banana, 바나나 in BST
There is apple, 사과 in BST
There is pineapple, 파인애플 in BST
There is orange, 오랜지 in BST
There is no apple in BST
해시 테이블을 이용한 맵(딕셔너리) 구현
#include <stdio.h>
#include <string.h>
#define NODE 6
/*
자료 : { "banana : 바나나", "apple : 사과", "pineapple : 파인애플", "orange : 오랜지"}
기능1 추가 : 맵에 키, 값 쌍을 추가한다
기능2 삭제 : 맵에 키, 값 쌍을 제거한다
기능3 조회 : 맵에서 키를 통해 저장된 값을 확인한다.
*/
// 해시 함수
int hash(char* str) {
int length = strlen(str);
int ret = 0;
for (int i = 0; i < length; i++) {
ret += str[i];
}
return ret % 5;
}
//기능1 추가 : 집합에 원소를 추가한다
void insert(char* set[], char* key, char* data) {
int hashValue = hash(key);
set[hashValue] = data;
printf("%s is added to the set with %s by hash function\n\n", data, key);
}
//기능2 삭제 : 집합에서 원소를 삭제한다
void Delete(char* set[], char* key) {
int hashValue = hash(key);
if (!strcmp(set[hashValue], "x")) {
printf("%s is not in the set\n\n", key);
return;
}
set[hashValue] = "x";
printf("%s is deleted from the set\n\n", key);
}
//기능3 조회 : 집합에 원소가 속한지 확인한다
void search(char* set[], char* key) {
int hashValue = hash(key);
if (!strcmp(set[hashValue],"x")) {
printf("%s is not in the set\n\n", key);
}
else {
printf("%s, %s is in the set\n\n", key, set[hashValue]);
}
}
int main(void) {
char* set[NODE] = { "x", "x", "x", "x", "x", "x"};
// 매칭되는 원소가 없다면 -1로 해놓음
insert(set, "banana", "바나나");
insert(set, "apple", "사과");
insert(set, "pineapple", "파인애플");
insert(set, "orange", "오랜지");
search(set, "banana");
search(set, "apple");
search(set, "pineapple");
search(set, "orange");
Delete(set, "apple");
search(set, "apple");
}
결과창
바나나 is added to the set with banana by hash function
사과 is added to the set with apple by hash function
파인애플 is added to the set with pineapple by hash function
오랜지 is added to the set with orange by hash function
banana, 바나나 is in the set
apple, 사과 is in the set
pineapple, 파인애플 is in the set
orange, 오랜지 is in the set
apple is deleted from the set
apple is not in the set
마무리하며
역시나 맵도 해시를 이용한 자료구조이다 보니 해시 함수를 선택하는 과정이 중요하다.
또한, 해시 과정에서 충돌이 일어날 수도 있다.
그럴 때는 앞에서 배운 체이닝과 개방 주소법을 이용해서 같은 방식으로 처리를 해주면 된다.
일반적으로 BST를 이용한 맵과 집합은 추가/제거/탐색이 느리다. 반면에 중복 처리가 쉽고, 인덱스가 큰 경우 메모리를 아끼는 데 좋다.
반면에 해시 테이블을 이용한 맵과 집합은 추가/제거/탐색이 빠르다. 하지만 중복 처리가 복잡하며, 인덱스가 큰 경우 적재율이 낮아지고 메모리 낭비가 많아질 수 있다.
✅ 1. 해시 테이블을 통해, 맵(딕셔너리) ADT를 구현할 수 있다.
✅ 2. BST를 통해, 맵(딕셔너리) ADT를 구현할 수 있다.
💣 과제,
-
해시 함수를 수정해 충돌을 일으켜보고 체이닝으로 해결해본다.(난이도 中)
-
해시 함수를 수정해 충돌을 일으켜보고 개방 주소법으로 해결해본다.(난이도 中)
-
해시 함수를 수정해 충돌을 일으켜보고 구조체 수정으로 BST를 이용한 맵으로 해결해본다.(난이도 中)




Comments