9 min to read
C 언어(16) - 배열의 실체, 배열 포인터
C 언어 강의, 배열의 엄밀한 구조와 배열 포인터

🔚 짧게 하는 복습
✅ 1. 2차원 배열의 선언, 초기화, 탐색을 안다.
✅ 2. 3차원 배열의 선언, 초기화, 탐색을 안다.
✅ 3. 다차원 배열에 대해서 선언, 초기화, 탐색을 일반화할 수 있다.
혹시 기억이 안 난다면, 다시 돌아가자
우리는 지금까지 배열의 선언, 초기화, for 문을 통한 조작 등을 다루었다.
또한, 1차원에서 고차원으로 확장하는 방법도 배웠다.
하지만 아직 배열이 진짜 무엇인지는 엄밀하게 다루지 않았다.
12강에서 “배열은 자료구조 중 하나이며, 같은 자료형 변수를 여러 개를 연속적으로 다루는 구조라고 생각하면 좋다.”라고 다루었다.
어떻게 같은 자료형 변수 여러 개를 연속적으로 다루는 구조가 될 수 있는지 오늘 본격적으로 다루어보겠다.
배열의 특징
우선 변수 하나를 선언하면 어떤 일이 생긴다고 했는지 마지막으로 복습해보자. (자세한 내용은 여기로)
-
시작 주소를 랜덤하게 설정한다.
-
자료형에 맞게 공간을 할당한다.
-
어떤 값이 들어오면 그 공간에 저장한다.
여기서 중요한 점은 랜덤하게라는 점인데, 아래의 코드를 실행해보자.
#include<stdio.h>
int main() {
int var1, var2, var3;
printf("%d %d %d", &var1, &var2, &var3);
return 0;
//여러 번 실행해보며 3개의 주소 간 관계를 살펴보자
}
어떤 시스템에서는 3개의 숫자가 4씩 차이나는 규칙이 있을 수도 있지만, 대부분은 3개의 숫자는 아무 관련 없다.
즉 변수들에 배정되는 시작 주소는 무작위하다는 것이다. 아무리 같은 자료형이라도 변수들이 시작하는 주소는 관련이 없다.
반면에, 아래의 코드를 실행해보자.
int main() {
int vars[3] = {1, 2, 3};
printf("%d %d %d", &vars[0], &vars[1], &vars[2]);
return 0;
//여러 번 실행해보며 3개의 주소 간 관계를 살펴보자
}
vars[0] 시작 주소는 여전히 무작위지만, 이번에는 조금 다르다.
vars[0], vars[1], vars[2]는 각각 4씩 차이가 난다.
자료형을 바꿔서도 실행해보자, 놀랍게도 각각의 원소는 자료형의 크기만큼 주솟값이 차이가 난다.
이게 어떻게 된 일일까?
배열이 선언되는 원리
#include<stdio.h>
int main() {
int var1, var2, var3;
printf("%d %d %d", &var1, &var2, &var3);
return 0;
//여러 번 실행해보며 3개의 주소 간 관계를 살펴보자
}
이 코드가 실행될 때는
-
무작위의 var1 시작 주소가 정해진다.
-
int 크기로 변수 공간이 할당된다.
-
나머지 var2, var3도 1, 2번을 반복한다.
즉, 아래의 그림과 같다. (편의상 그림의 한 칸을 4바이트로, 변수의 주소는 임의로 설정 했다.)

하지만, 배열의 선언은 조금 원리가 다르다.
int main() {
int vars[3] = {1, 2, 3};
printf("%d %d %d", &vars[0], &vars[1], &vars[2]);
return 0;
//여러 번 실행해보며 3개의 주소 간 관계를 살펴보자
}
-
무작위로 배열의 시작 주소가 설정된다.
-
int 크기 * 배열 원소의 개수로 배열 공간이 할당된다.
-
시작 주소로부터 자료형 크기만큼의 공간은 각각 배열의 원소가 된다.
아래의 그림과 같다.

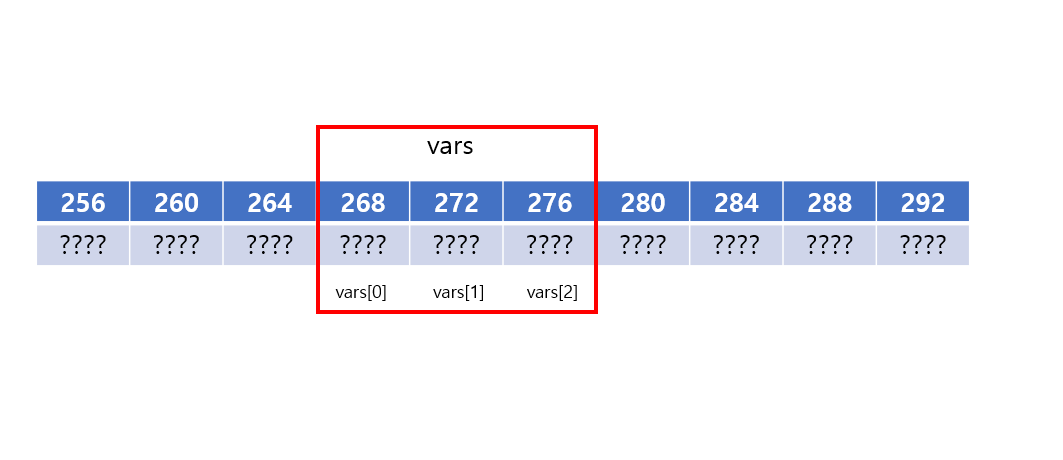
또한, 여기서 흥미로운 점이 있는데, 배열 이름은 그 자체로 배열의 시작 주소이다.
이게 무슨 말이냐면, &vars[0]과 vars, &vars는 모두 같은 값을 가진다.
포인터 연산의 비밀
이제 지금까지 풀었던 떡밥들을 모두 회수할 시간이다.
혹시 포인터의 연산에 대해 기억나는가? 기억 안 나거나 처음이면 여기로
포인터의 연산은 포인터와 정수의 덧, 뺄셈과 포인터 간의 뺄셈만 된다고 했다.
배운 내용을 요약하면 아래와 같다.
포인터 변수의 값에 정수를 더하면, 주소값에 +정수가 되는 것이 아니라 주솟값 + 정수*변수의 자료형의 크기
포인터끼리의 뺄셈은, 이 역시 단순히 주소값1 - 주소값2이 아니라 (주소값1 - 주소값2)/자료형의 크기
자 배열의 구조를 잘 생각해보자. &vars는 &vars[0]과 같고, &vars보다는 &vars[1]이 4만큼 크며, &vars보다는 &vars[2]가 8만큼 크다.
즉 n번째 인덱스를 가진 값은 &vars + n*자료형의 크기을 가진다.
이는 위의 요약을 이용하면 (&vars + n)의 값을 가진다는 뜻이며, &vars는 vars와 같으니 아래와 같은 코드를 만들 수 있다.
또한, 역참조 연산자를 이용하면 이런 간접 참조도 가능하다.
포인터끼리의 뺄셈은 여기서 예제로 다루진 않겠지만, 배열의 어떤 원소와 다른 원소 사이 얼마나 많은 원소가 사이에 들어가는지를 계산할 때 쓰일 것이라고 유추할 수 있다.
이렇듯, 포인터의 연산은 사실 배열에서 같은 자료형이 연속되어있다는 특징을 이용하기 위해 만들어진 것이다.
이차원 배열의 구조
1차원 배열은 메모리상의 연속된 공간을 할당해서 같은 자료형을 다룬다는 것을 배웠다.
그렇다면 2차원 배열은 어떨까? 메모리의 공간은 2차원이 아니라서 쉽게 예상이 가지 않는다.
직접 아래의 코드를 실행해서 확인해보자.
엥? 규칙이 보인다. vars[0][0], vars[0][1], vars[0][2], vars[1][0], vars[1][1], vars[1][2]가 1차원 배열처럼 순차적으로 저장되어있다.
아래의 코드 선언 과정을 살펴보자.
#include<stdio.h>
int main() {
int vars[][3] = {1, 2, 3, 4, 5, 6};
return 0;
}
-
vars의 시작 주소가 랜덤하게 할당된다.
-
vars의 행의 개수 * 열의 개수만큼 공간이 할당된다.
-
그 공간에서 행의 개수만큼 공간을 나눈다.
-
각 공간은 1차원 배열처럼 다루어진다.
그림으로 보면 조금 더 간단하다.

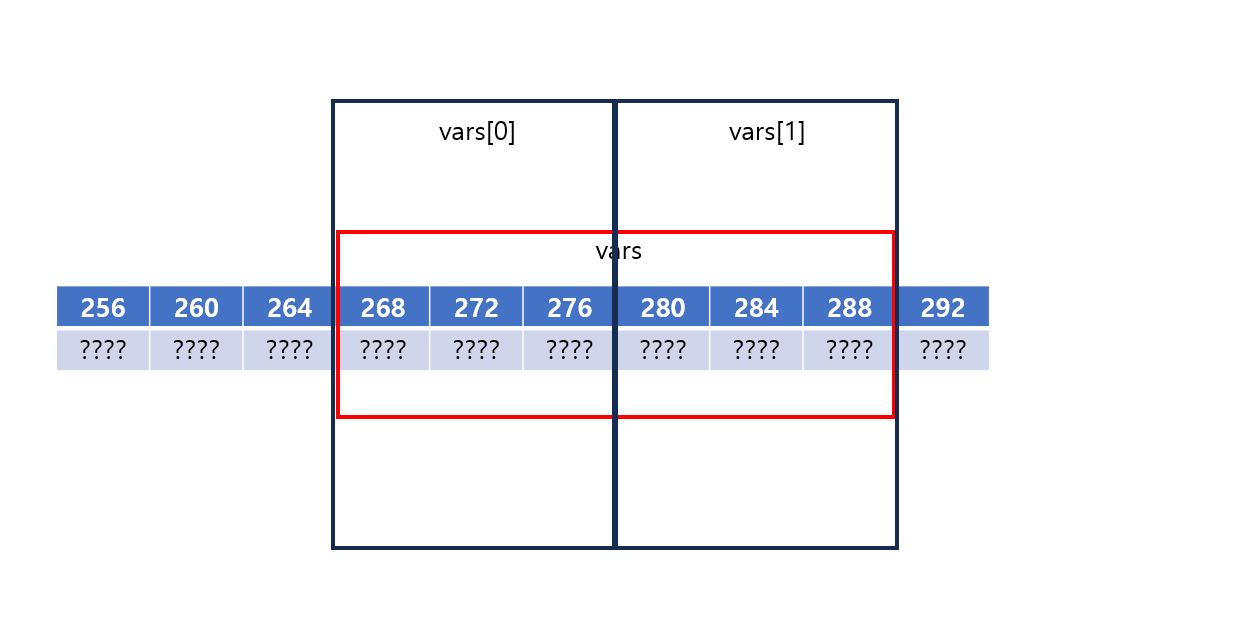
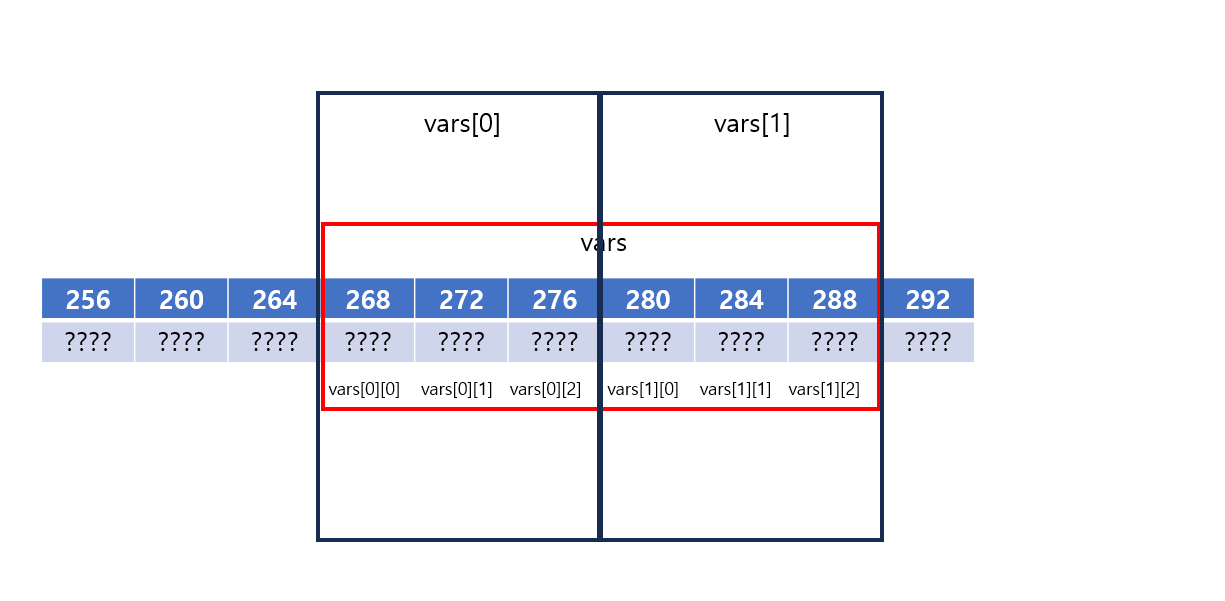
그런데 훌륭한 학생이라면 이렇게 질문할 수 있다. “그럼 같은 원소의 개수를 가진 1차원 배열과 다차원 배열은 저장되는 모습이 같은거 아닌가요?”
정확하다. 그렇다면 컴퓨터는 일차원 배열과 이차원 배열을 어떻게 구별할까?
힌트는, 각각 배열들의 선언 과정에 있다.
배열 포인터란?
정수형 변수의 시작 주소를 가리키는 포인터는 정수형 포인터(int*),
실수형 변수의 시작 주소를 가리키는 포인터는 실수형 포인터(double*),
문자형 변수의 시작 주소를 가리키는 포인터는 문자형 포인터(char*)라고 배웠다.
그렇다면 배열의 시작 주소를 가리키는 포인터는 무엇일까? 바로 배열 포인터이다.
일차원 배열의 포인터는 배열의 시작 주소 하나만 저장하면 되니까, 자료형 포인터와 차이가 없다. 아래의 코드를 보자.
그런데 이차원 배열의 포인터는 조금 원리가 다르다.
아래의 코드를 우선 보자.
#include<stdio.h>
int main() {
int vars[6] = {1, 2, 3, 4, 5, 6};
int vars2[2][3] = {(1, 2, 3), (4, 5, 6)};
int (*pvar)[3] = vars2; // 2차원 배열 포인터
int i, j;
for (i = 0; i < 2; i++) {
printf("%d ", *(pvar + i));
}
printf("\n");
for (i = 0; i < 2; i++) {
for (j = 0; j < 3; j++) {
printf("%d ", *(pvar + i) + j);
}
printf("\n");
}
return 0;
}
여기서 굉장히 헷갈리는데, 천천히 이차원 배열의 선언 과정과 함께 살펴보자.
이차원 배열은 1차원 배열과 다르게 각각의 행이 어디서 시작하는지에 대한 정보도 가질 수 있어야 한다.
어떠한 인덱스의 값을 참조하려면 아래와 같은 과정을 가지기 때문이다.
-
시작 주소에서 각 행의 시작 주소로 간다.
-
그 행에서 그 인덱스의 값을 가진 원소만큼 이동한다.
즉 이차원 배열의 포인터라는 것은 시작 주소 -> 행의 시작 주소의 정보를 저장할 수 있어야 한다. 그렇기에 이차원 포인터가 사용되어야 한다.
또한, 그 포인터의 자료형 크기는 시작 주소에서 행의 시작 주소로 이동할 때,
시작 주소에서 정수 연산으로 바로 참조하려면, 각 행이 가지는 1차원 배열의 크기를 가져야 한다. (정수 연산은 정수 * 자료형의 크기만큼 움직이니까)
그렇기에 이차원 배열 포인터 자체의 값은 배열의 시작 주소를 가지고, n만큼 덧셈한 값은 n번째 행의 시작 주소를 가진다.
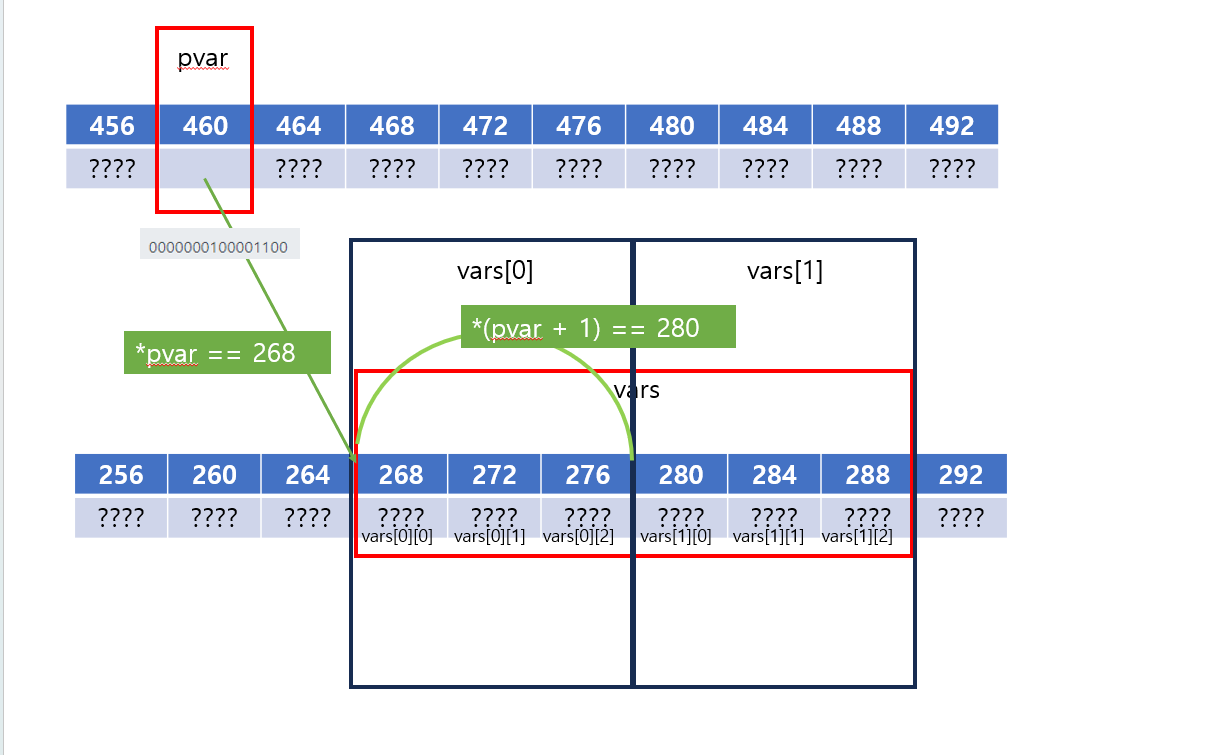
그다음은 한 번 간접 참조된 이차원 포인터이니까, 그 행의 일차원 배열 포인터와 같이 다루어진다.
각 행의 1차원 배열 포인터의 자료형이 정수이니, m만큼 덧셈하면 n번째 행의 m번째 인덱스를 가진 값의 시작 주소를 가지게 된다.
[] 연산자의 비밀
배열에서 직접 참조를 할 때 쓰는 []는 사실 연산자이다.
2가지의 값이 필요한 이항연산자로, 변수[정수]의 모습일 때 *(&변수 + 정수)의 값을 가진다.
그렇기에, arr[1]은 *(arr+1), arr[1][2]는 왼쪽부터 *(*(arr+1)+2)를 가지는 것이다.
배열 이름의 비밀
1차원 배열 포인터가 일반 포인터이고, 2차원 배열 포인터가 이중 포인터이다.
그런데도 똑같이 배열 이름으로 배열의 시작 주소로 넘겨줄 수 있다.
정수형 포인터는 정수형 변수의 주소만, 실수형 포인터는 실수형 변수의 주소만 주는 것 처럼, 같은 자료형의 주소만 줄 수 있다.
이것처럼, 1차원 배열 포인터에 값을 줄 때랑, 2차원 배열 포인터에 값을 줄 때도 각각은 같은 차원을 가져야한다는 뜻이다.
이 말은 다르게 말하면, 각각의 배열 이름은 설령 같은 이름을 가져도 상황에 따라 다른 차원을 가진다는 의미이다.
이는 1차원 배열 이름을 포인터로 사용하면 그 배열의 첫 번째 요소를 가리키는 포인터처럼 동작하고 2차원 배열 이름을 포인터로 사용하면 첫 번째 행의 시작 주소를 반환한다 이중 포인터처럼 동작하기 때문이다.
즉, 1차원과 2차원 배열의 이름이 같은 주소를 가리키더라도, 그것이 의미하는 차원이 다르다는 것이다.
이는 선언시에 비밀이 있는데, 우리가 처음 선언할 때 []이 얼마나 붙었냐에 따라 컴퓨터가 배열 이름라는 변수는 n중 포인터처럼 작동된다.
이 때문에 비록 메모리상 저장되는 결과는 같을 수 있지만, 배열의 차원에 따라 같은 상황이 아니라는 것이다.
📖 오늘의 핵심(다 알기 전까지는 넘어가지 말자❗)
✅ 1. 배열의 메모리 구조를 안다.
✅ 2. 1차원 배열 포인터를 이용해 간접 참조를 한다.
✅ 3. 2차원 배열 포인터를 이용해 간접 참조를 한다
✅ 4. [] 연산자를 안다.
✅ 5. 배열 이름의 의미를 이해한다.
⚠️ 1차원과 2차원 배열의 이름이 같은 주소를 가리키더라도, 그것이 의미하는 차원이 다르다.
⚠️ 다차원 배열 포인터는 매우 헷갈리는데 포인터의 연산과 다중 포인터를 이용해 이해하자.
💣 과제,
- 3차원 배열 포인터를 만들어보고 간접 참조해보자. (난이도 下) (int (*ptr)[][]으로 선언한다.)
🔜 더 공부해보기,




Comments