3 min to read
C 언어(5) - 자료형 더 깊게 이해하기(아스키 코드)
C 언어 강의 - 아스키 코드

🔚 짧게 하는 복습
✅ 1. 부동 소수점 및 편향 지수에 대해 알자.
✅ 2. 지수부의 모든 비트가 0, 1일 때의 특수한 상황에 대해서 알자.
✅ 3. 왜 오차가 여전히 많은 방식을 정수든 실수든 채택하고 사용하는지 알아보자.
혹시 기억이 안 난다면, 다시 돌아가자
이제 자료형 시리즈가 거의 끝났다.
이때까지 정수형, 실수형을 하면서 이진법을 하느라 머리가 엄청 아팠을 텐데 고생했다고 말하고 싶다.
사실 이진법은 컴퓨터 구조를 듣고 다시 보면 이해가 잘 될 텐데, 아무튼 처음 배울 때는 쉽지 않다.
오늘은 마지막 자료형, 문자형을 알아보자.
문자형의 정체
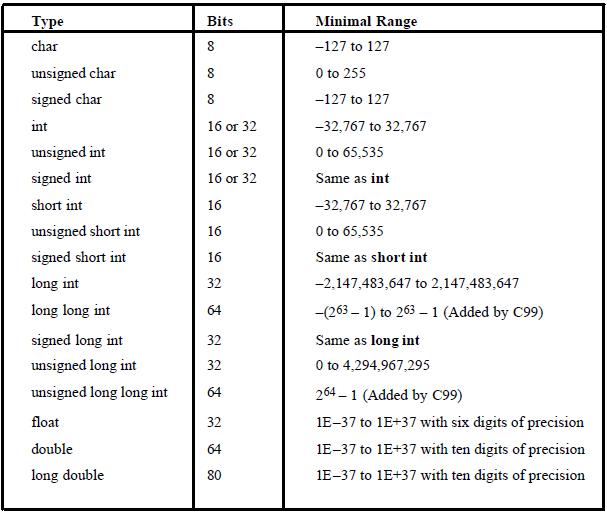
이 그림을 보았다면, 의아한 점이 생길 것이다. 문자형의 출력범위가 정수이다..!
더욱 이상한 것은 부호도 있다.
한번 흥미로운 실험을 해보자.
원래 char형의 형식 지정자는 %c지만 char형 변수에 문자 ‘A’를 넣고 %d로 한 번 출력을 해보자.
그리고 int형 변수에 -15를 넣고 %d가 아니라 %c로 출력해보자.
필자를 포함한 몇몇 분들은 코드 자체가 이렇게 잘 돌아갈 것이다.
하지만 또 몇몇 컴퓨터에서는 다른 값이나, 오류가 나오기도 한다.
누구의 컴퓨터가 잘못일까?? 사실을 둘 다 틀린 것이 아니다.
오늘은 왜 이런 결과가 나오는지에 대해서 알아보자.
아스키코드란?
정수와 실수를 넣는 방법을 고생해서 만들었던 것과 달리, 문자는 생각보다 간단하게 해결되었다.
그 이유는 예전부터 인쇄전신기에서 사용하던 ASCII(American Standard Code for Information Interchange, 미국 정보 교환 표준 부호)가 이미 발명되었기 때문이었다.
이는 아스키코드라고 불리며, 0 ~ 127까지 문자들을 숫자로 매칭시켜서 표현하는 방법이었다.
아래와 같이 매칭된다.
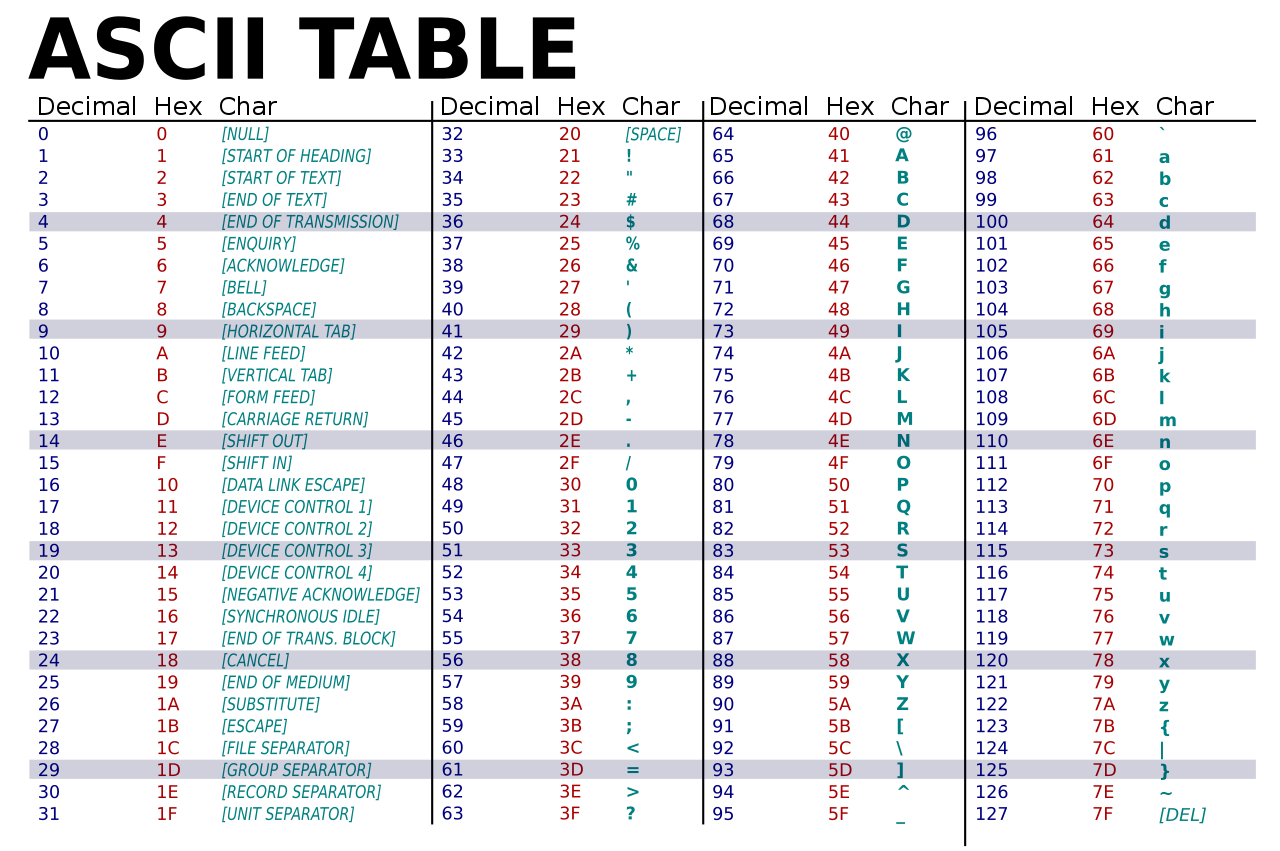
이것이 바로 char형의 표현 범위가 정수형으로 나타나는 이유이다.
실제로 정수형과 마찬가지로 char형은 signed는 2의 보수법, unsigned는 이진법을 근간으로 표현이 된다.
그런데 127까지 표현하는 거면 사실 7bit만 해도 충분하다. 그런데도 1bit를 더 쓰는 이유는 언급한 것처럼 인쇄전신기로 쓰였기 때문에 요즘의 해킹처럼 누군가에 의해 조작이 될 수 있었다.
그래서 패리티 비트라고 신호가 중간에 누군가에 의해 변질됬는지 확인하기 위해 비트를 하나 더 추가하던 것에서 왔다.
물론 지금은 패리티 비트로써 사용하지 않는다!
그러면 나머지는…?
signed 같은 경우 0 ~ 127까지만 할당되어있다면, -127 ~ -1까지는 비어있는 걸까?
unsigned 같은 경우는 128 ~ 255까지는 어떻게 되는 걸까?
우선 첫 번째부터 이야기하자면 음수에 해당하는 문자는 없다.
그렇다면 아까 왜 -15를 넣었을 때 어떤 문자가 나온 걸까?
이는 프로그램을 돌리는 곳마다, 컴파일러라는 것이 다른데
어떤 컴파일러는 오류를 내고, 어떤 컴파일러는 언더플로우가 발생하며, 어떤 컴파일러는 예측할 수 없는 값이 나온다..
즉 일관성 없는 결과가 나온다는 말은 문자형은 문자를 나타내는 데 사용해야지, 이상한 용도로 쓰면 안 된다는 뜻이다
그다음은 두 번째 이야기이다. 그럼 128부터 255까지는 어떻게 되어있을까?
이 역시 컴파일러마다 처리가 다르지만, 일반적으로 대부분 컴파일러는 128에서 255까지를 “확장된 아스키코드(Extended ASCII)”로 매칭시킨다.
이는 아스키코드의 문자가 부족함을 느끼고, 남은 부분에 더 문자를 할당한 것이다.
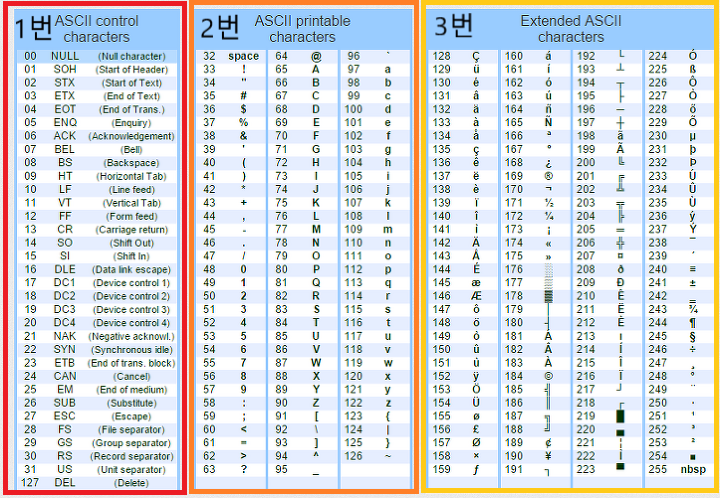
그럼 문자형은 여기서 끝..?
일단은 C언어에서는 문자형은 이게 끝이다. 굳이 아스키코드를 외울 필요는 없다.
우리가 직접 아스키코드를 외워서 쓸 일은 없기 때문이다. 언급한 것처럼 그런 행동은 없어야한다.
그런데 이렇게 마치기 전에… 만약 문자형이 여기서 끝이라면 이 블로그에 적힌 포스트, 이건 어떻게 된 일일까?
눈을 씻고 찾아봐도 확장된 아스키코드마저 한국어는 없다.
유니코드의 등장
원래 확장된 아스키코드 전에 남은 1bit에는 각국의 언어를 집어넣었다.
그런데 한글을 생각해보면, 1bit로 표현될 리가 없다. 그 많은 경우의 수와 조합이 표현되기에는 1bit는 턱없이 모자랐다.
그뿐만 아니라, 여러 나라에서 전 세계 공용의 문자표현이 필요하다고 느꼈고, 4바이트, 32bit의 표현 방식인 유니코드가 등장하게 된다.(경우의 수로 42억)
거의 모든 문자를 다 넣었지만, 아직 반도 차지 않았고, 아마 앞으로도 문자의 표현이 부족해서 새로운 방법이 만들어질 일은 거의 없을 것 같다.
📖 오늘의 핵심(다 알기 전까지는 넘어가지 말자❗)
✅ 1. C언어에서 문자형은 0 ~ 127까지 ASCII 코드, 혹은 0~256까지 Extended ASCII 코드로 할당된다.
⚠️ formatting, 변수 선언은 꼭 같은 자료형끼리만 하자. 오늘 보여준 것은 예일 뿐 실제로 이렇게 사용하면 안 된다.
💣 과제, 없음
🔜 더 공부해보기,




Comments