21 min to read
자료구조(16) - DFS와 BFS
깊이 우선 탐색(DFS)와 너비 우선 탐색(BFS)

🔚 짧게 하는 복습
✅ 1. 인접 행렬과 인접 리스트를 안다.
혹시 기억이 안 난다면, 다시 돌아가자
저번 시간까지, 그래프를 기본적으로 구현하는 방법에 대해 배웠다.
인접 행렬과 인접 리스트를 이용하면 그래프를 구현할 수 있다는 것을 배웠다.
우리는 행렬과 리스트의 성질을 이용하면, 정점의 추가/ 수정/ 삭제도 쉽다는 것을 이해할 수 있다.
그렇다면 대표적인 ADT 중 하나, 조회와 순회는 어떻게 해야 할지 생각해보자.
지금까지 잘 따라왔다면, 사실 순회와 조회의 작동 방식이 근본적으로 다르지 않다는 것을 알 것이다.
조회는 순회하다가 원하는 값을 찾으면 성공, 아니면 실패이기 때문이다.
즉, 순회만 잘 구현하면 된다는 뜻이다.
참고로 이번 강의는 매우 매우 중요하다.
스택, 큐, 연결리스트, 배열 등 트리를 제외한 모든 자료형을 복습할 수 있으므로 꼭 손으로 구현해보길 바란다.
DFS와 BFS란?
그래프 순회를 보기 전, 트리의 순회부터 복습해보자.
우리는 preorder, inorder, postorder, level-order 총 4개를 배웠다.
하지만 작동 방식으로 생각하면, 사실 2가지 방식으로 나뉜다.
하나는 루트에서 리프들을 하나씩 방문하는 방법(preorder, inorder, postorder)으로 아래 이미지와 같고,
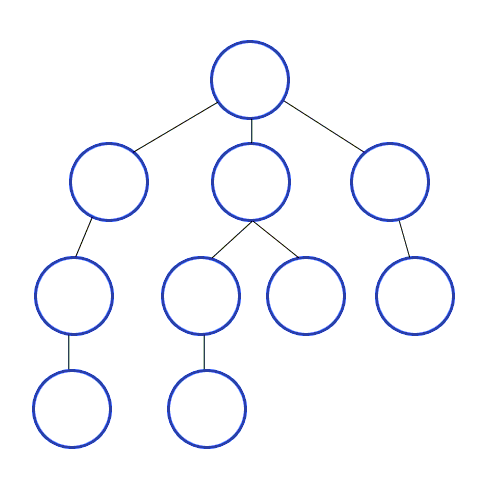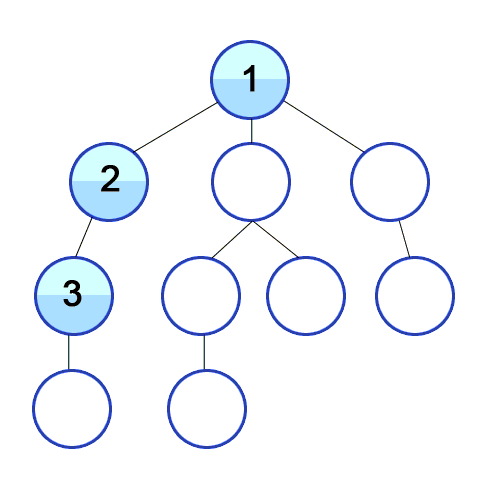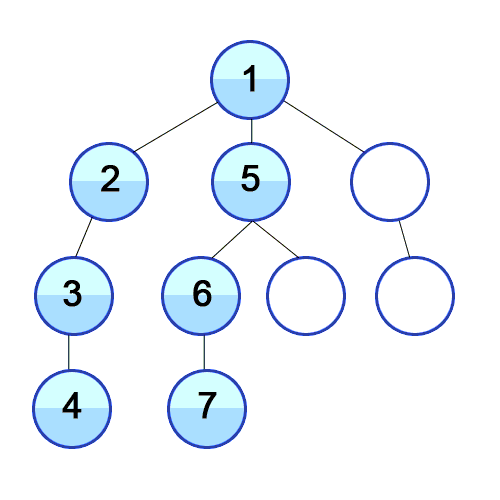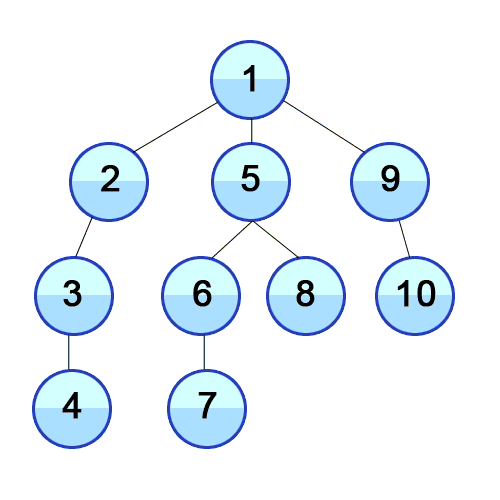
다른 하나는 level마다 방문하는 level-order traversal으로 아래 이미지와 같다.
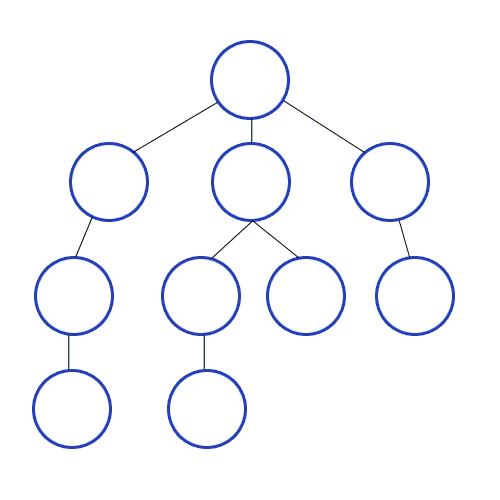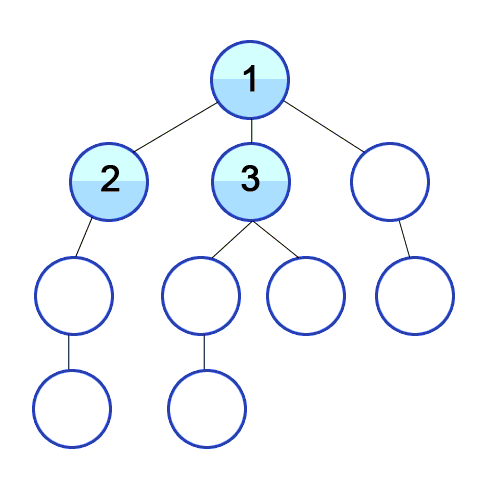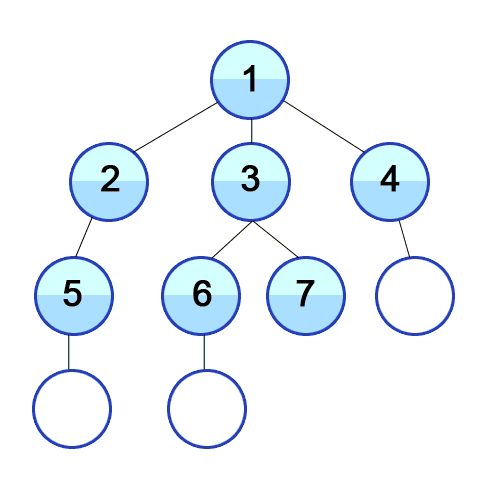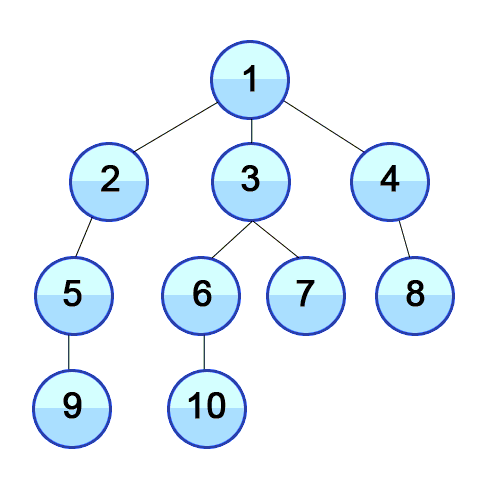
여기서 이 두 가지 방법으로 일반화하여 그래프의 탐색도 다루려고 한다.
첫 번째 방식과 비슷하게 동작하는 그래프 탐색을 깊이 우선 탐색(DFS), 두 번째 방식과 비슷한 동작을 하는 것은 너비 우선 탐색(BFS)이라고 한다.
조금 더 명확하게 정의하자면 DFS는 아래와 같은 탐색 방법을 의미한다.
-
임의의 정점을 스택에 입력한다.
-
스택에서 정점을 하나 꺼내고 방문 처리한다, 그리고 그 정점과 인접한 정점 중 방문하지 않은 정점이 있다면 모두 스택에 넣는다.
-
2번을 반복한다.
-
더 이상 방문할 곳이 없다면 종료한다.
즉, 그래프의 DFS는 아래와 같이 동작한다.
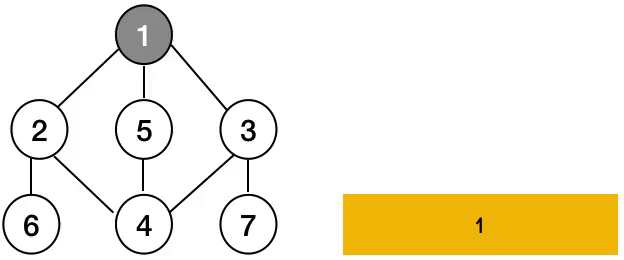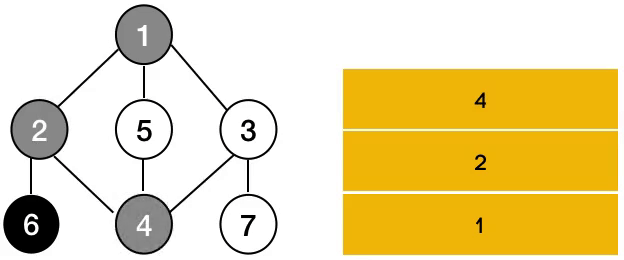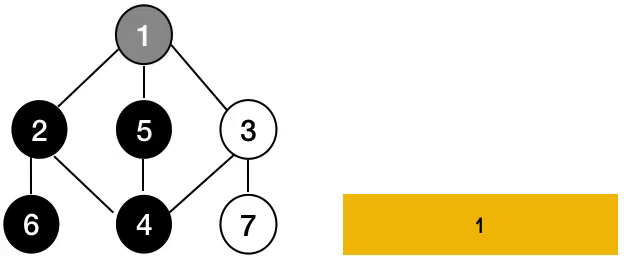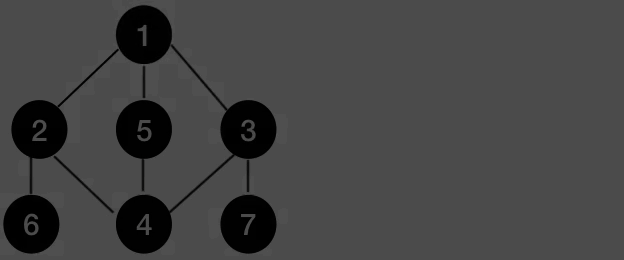
반면에, BFS는 아래와 같은 동작으로 정의된다.
-
임의의 정점을 큐에 입력한다.
-
큐에서 정점을 하나 꺼내고, 그 정점에 인접한 정점 중 방문하지 않은 정점들을 방문 처리 후 큐에 입력한다.
-
2번을 반복한다.
-
큐에 더 이상 방문할 정점이 없다면 종료한다.
즉, 그래프의 BFS는 아래와 같이 동작한다.
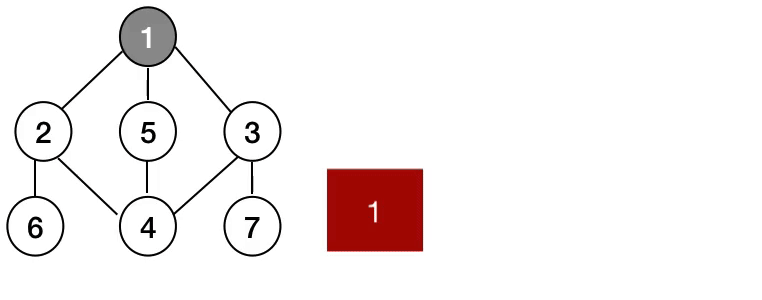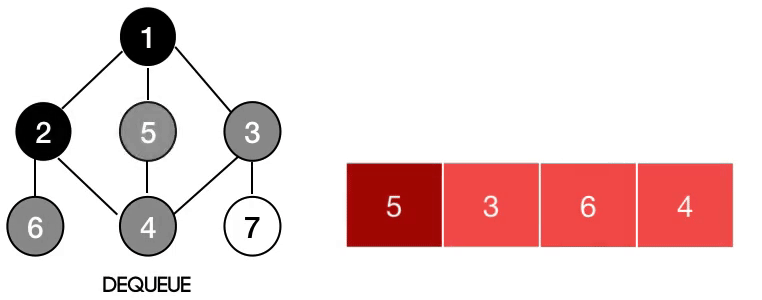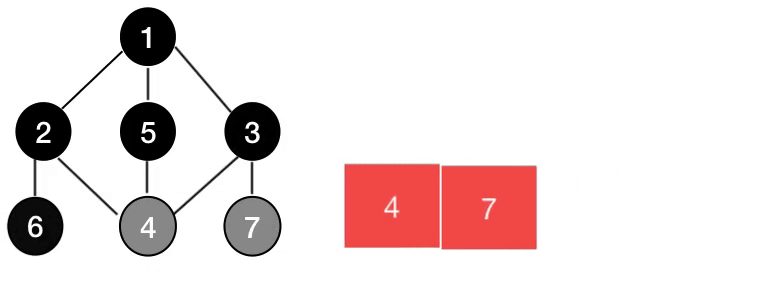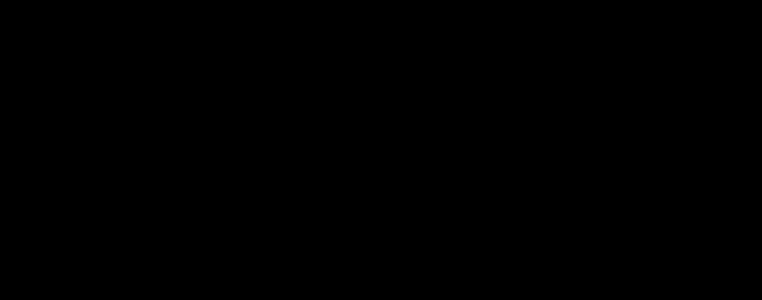
깊이 우선 탐색(DFS)과 너비 우선 탐색(BFS)의 구현
앞의 그림을 보면 알겠지만, DFS와 BFS의 핵심은 스택과 큐이다.
위 그림 속 그래프를 우선 구현해보고, DFS와 BFS를 구현해보겠다.
꼭 먼저 구현해보고, 아래를 읽어보도록 하자.
수업을 잘 따라와서 큐와 스택을 구현한 파일이 있다면 헤더로 포함해서 사용해도 좋다.
인접 행렬을 이용한 DFS, 인접 리스트를 이용한 DFS, 인접 행렬을 이용한 BFS, 인접 리스트를 이용한 BFS 총 4가지 사항을 구현해보겠다.
우선 인접 행렬부터 다루어보겠다.
인접 행렬를 이용한 DFS와 BFS
#include <stdio.h>
#include <stdlib.h>
#include "stack.h" // 만들어 놓은 자료구조 스택을 사용
#define NODE 7// 상수를 이용한 NODE 수 저장
enum status { FALSE, TRUE }; // ENUM 상수를 이용해 참, 거짓 표기
typedef struct input {
int vertex1;
int vertex2;
}info;
void make_graph(int matrix[][NODE+1], info arr[], const int arr_size) {
for (int i = 0; i < arr_size; i++) {
int v1 = arr[i].vertex1;
int v2 = arr[i].vertex2;
matrix[v1][v2] = 1;
matrix[v2][v1] = 1;
// 무향 그래프이니까
}
}
void dfs(int matrix[][NODE + 1], int visited[], int index) {
stack st = NULL;
int top = 0;
// 만들어둔 스택 사용!
insert(&st, index, &top);
// 1. 임의의 정점을 스택에 입력한다.
visited[index] = TRUE;
// 방문했다고 표시
while(!is_empty(top)){
int cur_vertex = find_top(st, top);
printf("%d ", cur_vertex);
pop(&st, &top);
//2. 스택에서 정점을 하나 꺼낸다.
for (int i = 1; i <= NODE; i++) {
if (matrix[cur_vertex][i] == 1 && visited[i] == FALSE) {
insert(&st, i, &top);
visited[i] = TRUE;
//인접한 방문하지 않은 정점이 있다면 모두 스택에 넣는다.
}
}
}
//3. 2번을 반복한다.
//4. 더 이상 방문할 곳이 없다면 종료한다.
free(st);
}
int main(void) {
int adj_matrix[NODE+1][NODE+1] = {0, };
int visited[NODE+1] = { FALSE, };
//편한 인덱싱을 위해서 1씩 증가
info arr[] = { {1, 2}, {1, 5}, {1,3}, {2, 6}, {2, 4}, {5,4}, {3,4}, {3,7} };
// 정점 연결 정보
int arr_size = sizeof(arr) / sizeof(info);// 연결 정보 개수
make_graph(adj_matrix, arr, arr_size);
dfs(adj_matrix, visited, 1);
}
결과
1 5 4 3 7 2 6
DFS의 핵심은 stack을 잘 구현하고 visited를 배열을 이용해서 방문을 점검하는 것에 있다.
stack과 배열을 ADT 및 구현만 하고 말았는데, 이렇게 실제로 다루니까 자료구조도 복습하기에도 좋다.
거의 똑같은 구조를 queue로만 바꿔주면 BFS도 구현이 가능하다.
#include <stdio.h>
#include <stdlib.h>
#include "queue.h" // 만들어 놓은 자료구조 스택을 사용
#define NODE 7// 상수를 이용한 NODE 수 저장
enum status { FALSE, TRUE }; // ENUM 상수를 이용해 참, 거짓 표기
typedef struct input {
int vertex1;
int vertex2;
}info;
void make_graph(int matrix[][NODE+1], info arr[], const int arr_size) {
for (int i = 0; i < arr_size; i++) {
int v1 = arr[i].vertex1;
int v2 = arr[i].vertex2;
matrix[v1][v2] = 1;
matrix[v2][v1] = 1;
// 무향 그래프이니까
}
}
void bfs(int matrix[][NODE + 1], int visited[], int index) {
Queue q = NULL;
int front = 0;
int rear = 0;
// 만들어둔 큐 사용!
insert(&q, index, &rear);
// 1. 임의의 정점을 큐에 입력한다.
visited[index] = TRUE;
// 방문했다고 표시
while(!is_empty(rear, front)){
int cur_vertex = find_front(q, rear, front);
printf("%d ", cur_vertex);
pop(&q, &rear, &front);
//2. 큐에서 정점을 하나 꺼낸다.
for (int i = 1; i <= NODE; i++) {
if (matrix[cur_vertex][i] == 1 && visited[i] == FALSE) {
insert(&q, i, &rear);
visited[i] = TRUE;
//인접한 방문하지 않은 정점들을 방문처리 후 큐에 입력한다.
}
}
}
//3. 2번을 반복한다.
//4. 더 이상 방문할 곳이 없다면 종료한다.
free(q);
}
int main(void) {
int adj_matrix[NODE+1][NODE+1] = {0, };
int visited[NODE + 1] = { FALSE, };
//편한 인덱싱을 위해서 1씩 증가
info arr[] = { {1, 2}, {1, 5}, {1,3}, {2, 6}, {2, 4}, {5,4}, {3,4}, {3,7} };
// 정점 연결 정보
int arr_size = sizeof(arr) / sizeof(info);// 연결 정보 개수
make_graph(adj_matrix, arr, arr_size);
bfs(adj_matrix, visited, 1);
}
결과
1 2 3 5 4 6 7
코드에 들어가는 자료구조만 다르지, 사실 똑같은 구조임을 알 수 있다!
어떤 자료구조가 들어가느냐에 따라 얼마나 방향이 바뀔 수 있는지 알 수 있었다.
이제는 인접 리스트를 이용해서 DFS와 BFS를 구현해보겠다.
인접 리스트를 이용한 DFS와 BFS
#include <stdio.h>
#include <stdlib.h>
#include "linked_list.h"
#include "stack.h" // 만들어 놓은 자료구조 스택을 사용
#define NODE 7// 상수를 이용한 NODE 수 저장
enum status { FALSE, TRUE }; // ENUM 상수를 이용해 참, 거짓 표기
typedef struct input {
int vertex1;
int vertex2;
}info;
void make_graph(nodePointer list[], info arr[], const int arr_size) {
for (int i = 0; i < arr_size; i++) {
int v1 = arr[i].vertex1;
int v2 = arr[i].vertex2;
push_back(&list[v1], v2);
push_back(&list[v2], v1);
// 무향 그래프이니까
}
}
void dfs(nodePointer list[], int visited[], int index) {
stack st = NULL;
int top = 0;
// 만들어둔 스택 사용!
insert(&st, index, &top);
// 1. 임의의 정점을 스택에 입력한다.
visited[index] = TRUE;
// 방문했다고 표시
while (!is_empty(top)) {
int cur_vertex = find_top(st, top);
printf("%d ", cur_vertex);
pop(&st, &top);
//2. 스택에서 정점을 하나 꺼낸다.
for (int i = 1; i <= NODE; i++) {
if (search(list[cur_vertex], i) && visited[i] == FALSE) {
insert(&st, i, &top);
visited[i] = TRUE;
//인접한 방문하지 않은 정점이 있다면 모두 스택에 넣는다.
}
}
}
//3. 2번을 반복한다.
//4. 더 이상 방문할 곳이 없다면 종료한다.
free(st);
}
int main(void) {
nodePointer list[NODE + 1] = { NULL, };
int visited[NODE + 1] = { FALSE, };
//편한 인덱싱을 위해서 1씩 증가
info arr[] = { {1, 2}, {1, 5}, {1,3}, {2, 6}, {2, 4}, {5,4}, {3,4}, {3,7} };
// 정점 연결 정보
int arr_size = sizeof(arr) / sizeof(info);// 연결 정보 개수
make_graph(list, arr, arr_size);
dfs(list, visited, 1);
}
인접 행렬의 코드와 거의 똑같은데, 역시 인접 행렬이 인접 리스트로만 바뀐 것을 알 수 있다.
연결리스트의 search는 다루지 않았는데, 이는 순회 및 수정을 다뤘으니 충분히 구현할 수 있을 거로 생각한다.
아래의 결과를 보면, 인접 행렬의 결과와 똑같음을 알 수 있다.
결과
1 5 4 3 7 2 6
마지막으로 인접 리스트의 bfs까지 다루고 마치겠다.
#include <stdio.h>
#include <stdlib.h>
#include "linked_list.h"
#include "queue.h" // 만들어 놓은 자료구조 스택을 사용
#define NODE 7// 상수를 이용한 NODE 수 저장
enum status { FALSE, TRUE }; // ENUM 상수를 이용해 참, 거짓 표기
typedef struct input {
int vertex1;
int vertex2;
}info;
void make_graph(nodePointer list[], info arr[], const int arr_size) {
for (int i = 0; i < arr_size; i++) {
int v1 = arr[i].vertex1;
int v2 = arr[i].vertex2;
push_back(&list[v1], v2);
push_back(&list[v2], v1);
// 무향 그래프이니까
}
}
void bfs(nodePointer list[], int visited[], int index) {
Queue q = NULL;
int front = 0;
int rear = 0;
// 만들어둔 큐 사용!
insert(&q, index, &rear);
// 1. 임의의 정점을 큐에 입력한다.
visited[index] = TRUE;
// 방문했다고 표시
while (!is_empty(rear, front)) {
int cur_vertex = find_front(q, rear, front);
printf("%d ", cur_vertex);
pop(&q, &rear, &front);
//2. 큐에서 정점을 하나 꺼낸다.
for (int i = 1; i <= NODE; i++) {
if (search(list[cur_vertex], i) == 1 && visited[i] == FALSE) {
insert(&q, i, &rear);
visited[i] = TRUE;
//인접한 방문하지 않은 정점들을 방문처리 후 큐에 입력한다.
}
}
}
//3. 2번을 반복한다.
//4. 더 이상 방문할 곳이 없다면 종료한다.
free(q);
}
int main(void) {
nodePointer list[NODE + 1] = { NULL, };
int visited[NODE + 1] = { FALSE, };
//편한 인덱싱을 위해서 1씩 증가
info arr[] = { {1, 2}, {1, 5}, {1,3}, {2, 6}, {2, 4}, {5,4}, {3,4}, {3,7} };
// 정점 연결 정보
int arr_size = sizeof(arr) / sizeof(info);// 연결 정보 개수
make_graph(list, arr, arr_size);
bfs(list, visited, 1);
}
결과
1 2 3 5 4 6 7
재귀함수를 이용한 DFS
이번 강의가 코드가 정말 많고 길어지는 듯한데, 진짜 마지막이다.
DFS를 구현하는 데 있어서 스택을 사용하지 않고 더 간단하게 구현할 수 있다.
바로 C에 기본으로 내장된 스택을 이용하는 것인데, 바로 스택 프레임이다.
너무 오랜만이라 기억이 나지 않는다면, 아래 문서를 읽어보자.
다시 간단히 말하면,
프로그램에서 함수를 호출할 때마다 스택 프레임이라는 공간을 가진다.
이는 스택 구조처럼 LIFO 구조를 가져서, 마지막에 할당된 프레임일수록 제일 먼저 할당이 해제된다.
이를 이용하면 아래와 같이 함수를 짤 수 있다.
#include <stdio.h>
#include <stdlib.h>
#include "linked_list.h"
#define NODE 7// 상수를 이용한 NODE 수 저장
enum status { FALSE, TRUE }; // ENUM 상수를 이용해 참, 거짓 표기
typedef struct input {
int vertex1;
int vertex2;
}info;
void make_graph(nodePointer list[], info arr[], const int arr_size) {
for (int i = 0; i < arr_size; i++) {
int v1 = arr[i].vertex1;
int v2 = arr[i].vertex2;
push_back(&list[v1], v2);
push_back(&list[v2], v1);
// 무향 그래프이니까
}
}
void dfs(nodePointer list[], int visited[], int index) {
// 1. 현재 노드를 방문했다고 표시
visited[index] = TRUE;
// 2. 현재 노드 출력
printf("%d ", index);
// 3. 현재 노드와 연결된 방문하지 않은 인접 노드를 찾아서 재귀 호출
for (int i = 1; i <= NODE; i++) {
if (search(list[index], i) && visited[i] == FALSE) {
dfs(list, visited, i);
// 4. 재귀 호출을 통해 깊이 우선 탐색 진행
}
}
// 5. 현재 노드에서 더 이상 갈 곳이 없으면 종료
}
int main(void) {
nodePointer list[NODE + 1] = { NULL, };
int visited[NODE + 1] = { FALSE, };
//편한 인덱싱을 위해서 1씩 증가
info arr[] = { {1, 2}, {1, 5}, {1,3}, {2, 6}, {2, 4}, {5,4}, {3,4}, {3,7} };
// 정점 연결 정보
int arr_size = sizeof(arr) / sizeof(info);// 연결 정보 개수
make_graph(list, arr, arr_size);
printf("DFS : \n");
dfs(list, visited, 1);
}
아마 재귀 함수 부분이 이해가 안 될 것인데, 함수 호출이 종료하면 그 전 함수로 돌아간다는 점을 생각해보자.
DFS 함수의 탈출 조건은 더 이상 갈 곳이 없을 때이다.
즉, 인접한 노드가 없거나, 더 이상 방문할 곳이 없을 때까지 재귀 호출되는 것이니까 한 방향으로 진행된다.
이 원리로 깊이 우선 탐색(DFS)가 될 수 있는 것이다.
실제 그래프를 시각적으로 확인하고, 함수 호출과 함께 어떻게 진행되는지 그려보면 도움이 될 것이다.
참고로 이 코드의 결과는 위의 DFS 코드들의 결과와 다른데,
그 이유는 그래프의 특성에 따라 DFS의 결과는 하나가 아니기 때문이다
이는 BFS 또한 같다.
✅ 1. DFS와 BFS의 정의를 안다.
✅ 2. 인접 행렬의 DFS와 BFS를 구현할 수 있다.
✅ 3. 인접 리스트의 DFS와 BFS를 구현할 수 있다.
✅ 4. 재귀 함수를 이용해 DFS를 구현할 수 있다.
⚠️ 오늘 강의에서 DFS와 BFS가 이해 안 된다면 앞 강의들의 개념에 구멍이 났을 수도 있다. 복습을 철저히 하자.
⚠️ DFS와 BFS의 결과는 그래프에 따라 유일하지 않을 수 있다.
💣 과제,
-
유향 그래프의 DFS, BFS 코드를 짜보자.(난이도 下)
-
가중치가 있는 무향 멀티 그래프에서 가중치가 적은 엣지로만 DFS와 BFS 하는 코드를 짜보자. (난이도 上)
-
가중치가 있는 유향 멀티 그래프에서 가중치가 적은 엣지로만 DFS와 BFS 하는 코드를 짜보자. (난이도 上)
🔜 더 공부해보기,




Comments