12 min to read
자료구조(17) - 유니온 파인드
유니온 파인드

🔚 짧게 하는 복습
✅ 1. DFS와 BFS의 정의를 안다.
✅ 2. 인접 행렬의 DFS와 BFS를 구현할 수 있다.
✅ 3. 인접 리스트의 DFS와 BFS를 구현할 수 있다.
✅ 4. 재귀 함수를 이용해 DFS를 구현할 수 있다.
혹시 기억이 안 난다면, 다시 돌아가자
지난 수업에서는 그래프의 ADT와 이를 구현하는 방법에 대해 배웠다.
특히, 그래프의 순회에는 스택이나 재귀를 활용한 깊이 우선 탐색(DFS)과 큐를 이용한 너비 우선 탐색(BFS) 방법을 배웠다.
다음 강의에서는 그래프의 마지막 주제인 스패닝 트리를 다룰 예정이며, 이번 강의는 이 주제를 이해하기 위해 미리 유니온-파인드(Union-Find) 또는 서로소 집합(Disjoint Set)이라 불리는 자료구조를 다룬다.
서로소 집합이란?
서로소 집합(Disjoint-Set)이란 수학의 집합론에서 다루는 용어로 교집합이 없는 집합들을 말한다.
쉽게 말하면 집합들의 모임으로, 각각의 집합은 다른 집합과 공통 원소를 가지지 않는다는 것이다.
원소의 관점에서는 하나의 집합에만 속할 수 있다는 말이 된다.
전체 원소들을 몇 개의 집합으로 분류할 때 사용한다.
서로소 집합의 ADT는 굉장히 간단한데, Union과 Find 두 가지 기능이 필요하다.
Union이란 두 집합을 합치는 것을 의미하고, Find란 어떤 집합에 속해있는지를 반환하는 기능이다.
이 둘의 이름을 따서, 유니온-파인드(Union-Find) 자료구조라고 하기도 한다.
서로소 집합 ADT
역시나 ADT는 요구에 맞게 작성되는 것이기에, 절대적인 것이 아니라 필요에 맞게 수정할 수 있다.
서로소 집합 구현(트리 버전)
서로소 집합을 구현할 때는 트리 구조를 이용한다.
우선 전체 원소 수만큼 트리를 만든다. 처음에 각 트리는 루트 노드 하나만을 갖는다.
또, 각 루트 노드의 값은 원소의 값, 트리 포인터는 자기 자신을 가리키게 초기화한다.
이는 각 트리가 자기 자신만을 원소로 갖는 각각의 집합을 의미한다.
그리고 Union(합집합 연산)이 실행되면 2개의 원소를 입력받는다.
여기서 한 원소를 가진 트리의 트리 포인터를 다른 한 원소를 가진 트리를 가리키게 한다.
물론, 부모와 리프는 계층 구조를 갖는 것이 아니라 같은 집합임을 의미한다.
다만 루트 노드의 값을 집합을 대표하는 값으로 여기기 때문에, Find를 실행하면 한 원소를 입력받아 소속 트리의 루트 노드의 값을 반환한다.
아래의 그림을 보고 이해해 보자.
처음에 각 트리는 자신을 가리키며 초기화되어있다.

union(1,3)을 호출했고 1의 노드가 3을 가리킨다고 하자.
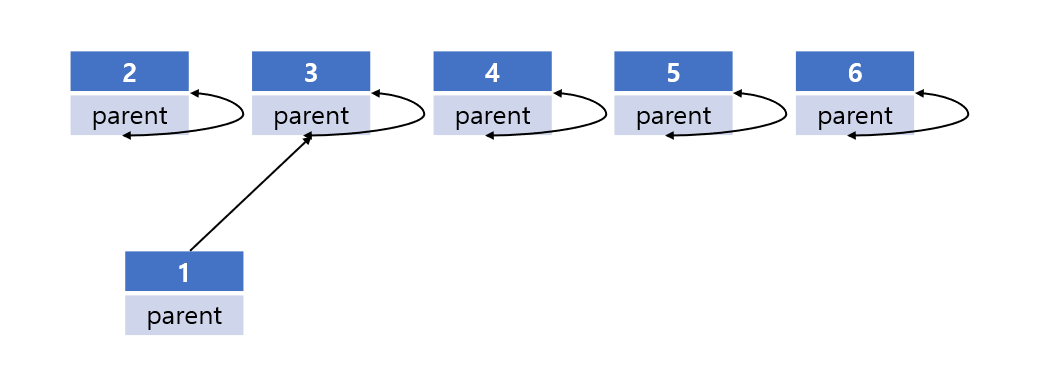
이렇게 바뀌면서, 1과 3은 하나의 집합이 된다. 둘을 find로 호출하면 루트 노드의 값인 3이 나온다.
여기서 union(3, 5)를 호출했다고 하자.
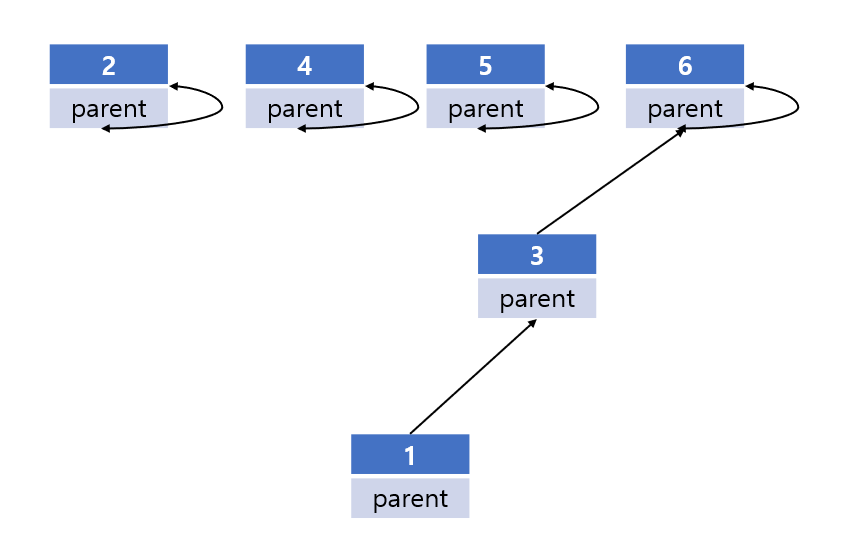
이번에도 1, 3, 5가 하나의 집합이 된 모습을 볼 수 있다. 역시 1, 3, 5 모두 find로 호출하면 루트 노드 값인 5가 나온다.
간단하므로, 직접 구현해보고 아래를 보자.
#include <stdio.h>
#include <stdlib.h>
#define NODE 6
/*
자료 : 정수
기능1 Union : 두 원소를 입력받아 두 원소가 속한 집합을 합친다.(합집합 연산)
기능2 Find : 원소를 입력받아 소속 집합의 루트 노드 값을 반환한다.
*/
typedef struct Node* treePointer;
typedef struct Node {
int value;
treePointer parent;
}node;
void init(treePointer arr[]) {
for (int i = 1; i <= NODE; i++) {
arr[i] = (treePointer)malloc(sizeof(treePointer));
arr[i]->value = i;
// 각 트리의 루트에 값을 입력한다.
arr[i]->parent = arr[i];
// 자신을 가리키도록 한다.
}
}// 초기화한다.
int _union(treePointer arr[], int a, int b) {
if (a == b) {
printf("%d and %d are same\n\n", a, b);
return -1;
// 같을 때 에러 처리
}
else if (a <= 0 || a > NODE) {
printf("There is no %d element\n\n", a);
return -1;
//a가 유효하지 않은 값일 때
}
else if (b <= 0 || b > NODE) {
printf("There is no %d element\n\n", b);
return -1;
//b가 유효하지 않은 값일 때
}
treePointer set_a = arr[a];
treePointer set_b = arr[b];
set_a->parent = set_b;
// 한 트리 포인터를 다른 트리 포인터를 가리키도록 함
return 0;
}
int find(treePointer arr[], int a) {
treePointer temp = arr[a];
while (temp->parent != temp) {
temp = temp->parent;
}
// 루트노드를 찾음
return temp->value;
}
int main(void) {
treePointer arr[NODE + 1] = { NULL , };
//전체 원소 수만큼 트리를 만들어야하기 때문에, 트리포인터 배열을 만든다.
init(arr); // 초기화 //{ {1}, {2}, {3}, {4}, {5}, {6} }
_union(arr, 1, 3); //{ {1, 3}, {2}, {4}, {5}, {6} }
_union(arr, 3, 5); //{ {1, 3, 5}, {2}, {4}, {6} }
_union(arr, 2, 4); //{ {1, 3, 5}, {2, 4}, {6} }
for (int i = 1; i <= NODE; i++) {
printf("%d is included by set %d\n\n", i, find(arr, i));
}
}
결과창
1 is included by set 5
2 is included by set 4
3 is included by set 5
4 is included by set 4
5 is included by set 5
6 is included by set 6
서로소 집합 구현(배열 버전)
이렇게 구현했을 때, 사실 함정이 있다.
굳이 배열의 원소가 트리 포인터일 필요가 없다는 점이다.
무슨 말인지 모르겠다면, 아래의 코드를 보자.
#include <stdio.h>
#include <stdlib.h>
#define NODE 6
/*
자료 : 정수
기능1 Union : 두 원소를 입력받아 두 원소가 속한 집합을 합친다.(합집합 연산)
기능2 Find : 원소를 입력받아 소속 집합의 루트 노드 값을 반환한다.
*/
void init(int arr[]) {
for (int i = 1; i <= NODE; i++) {
arr[i] = i;
}
}// 초기화한다.
int _union(int arr[], int a, int b) {
if (a == b) {
printf("%d and %d are same\n\n", a, b);
return -1;
// 같을 때 에러 처리
}
else if (a <= 0 || a > NODE) {
printf("There is no %d element\n\n", a);
return -1;
//a가 유효하지 않은 값일 때
}
else if (b <= 0 || b > NODE) {
printf("There is no %d element\n\n", b);
return -1;
//b가 유효하지 않은 값일 때
}
arr[a] = b;
return 0;
}
int find(int arr[], int a) {
if (a == arr[a]) {
return a; // 루트 노드
}
return find(arr, arr[a]);// 부모 노드로 재귀함수 호출
}
int main(void) {
int arr[NODE + 1] = { 0 , }; //전체 원소 수만큼 트리를 만들어야하기 때문에, 트리포인터 배열을 만든다.
init(arr); // 초기화 //{ {1}, {2}, {3}, {4}, {5}, {6} }
_union(arr, 1, 3); //{ {1, 3}, {2}, {4}, {5}, {6} }
_union(arr, 3, 5); //{ {1, 3, 5}, {2}, {4}, {6} }
_union(arr, 2, 4); //{ {1, 3, 5}, {2, 4}, {6} }
for (int i = 1; i <= NODE; i++) {
printf("%d is included by set %d\n\n", i, find(arr, i));
}
}
똑같은 코드를 복잡한 동적 할당을 안쓰고도 구현할 수 있었다.
그렇다면 조금만, 조금만 더 코드를 수정해보자.
여전히 코드에서 최적화할 부분이 있다.
서로소 집합 구현(최종 버전)
원소가 엄청 많고, 모두 한 집합으로 union된다고 생각해보자.
예를 들어, 이런 것이다.
for(int i = 1; i< 1000; i++){
_union(i, i+1);
} // 1 ~ 1000까지 모두 한 집합
이런 트리 구조를 만들었을 때, find(1)을 호출하면 1000번 find가 호출되면서 거꾸로 올라가야 한다.
이런 경우, 훨씬 빠르게 루트 노드를 구할 방법이 없을까?
재귀함수를 조금만 응용해서 서로소 집합을 구현하면, 이 문제를 해결할 수 있다.
예를 들어, 아래 사진을 보자.
이 사진에서, 이렇게 만들면 어떨까?
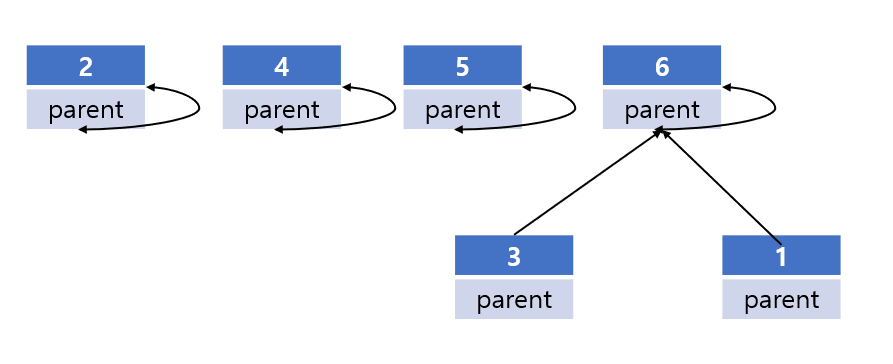
즉, 루트를 제외한 다른 모든 노드를 루트 노드로 직접 가리키게 하는 것이다.
이를 구현하는 과정은 생각보다 더 간단한데, union 함수와 find 함수에 몇 줄만 더 넣으면 된다.
int find(int arr[], int a) {
if (a == arr[a]) {
return a; // 루트 노드
}
return arr[a] = find(arr, arr[a]);
// 부모 노드로 재귀함수 호출
// 동시에, 루트 노드 값을 자신의 모든 조상 노드들에 루트 노드값에 저장.
}
int _union(int arr[], int a, int b) {
if (a == b) {
printf("%d and %d are same\n\n", a, b);
return -1;
// 같을 때 에러 처리
}
else if (a <= 0 || a > NODE) {
printf("There is no %d element\n\n", a);
return -1;
//a가 유효하지 않은 값일 때
}
else if (b <= 0 || b > NODE) {
printf("There is no %d element\n\n", b);
return -1;
//b가 유효하지 않은 값일 때
}
int root_a = find(arr, a);
int root_b = find(arr, b);
//각각의 루트를 구함.
arr[root_a] = root_b;
// 루트와 루트를 곧바로 연결
return 0;
}
물론, 이렇게 되면 union 안에 find가 들어가기 때문에 함수 정의의 순서를 바꿔줘야 한다.
(union을 먼저 선언하면, 도중에 나오는 find가 무엇인지 컴파일러는 모르기 때문이다.)
또한, 이렇게 서로소 집합에서 루트 노드로 직접 연결하는 방법을 경로 압축이라고 한다.
✅ 1. 서로소 집합(유니온 파인드) 정의를 안다.
✅ 2. 서로소 집합(유니온 파인드)의 ADT를 구현할 수 있다.
✅ 3. 경로 압축을 통해서 서로소 집합(유니온 파인드)의 ADT를 구할 수 있다.
⚠️ 서로소 집합(유니온 파인드)은 다음 시간에 바로 적용되는 자료구조이므로 꼭 이해하고 넘어가자.
💣 과제, 없음
🔜 더 공부해보기,




Comments