10 min to read
자료구조(19) - 집합과 해시 테이블
해시 테이블을 통한 집합

🔚 짧게 하는 복습
✅ 1. 최소 스패닝 트리(Minimum Spanning Tree)의 뜻을 안다.
✅ 2. 크루스칼 알고리즘을 통해서 최소 스패닝 트리를 구할 수 있다.
✅ 3. 프림 알고리즘을 통해서 최소 스패닝 트리를 구할 수 있다.
혹시 기억이 안 난다면, 다시 돌아가자
우리는 저번 시간까지 거의 모든 자료구조의 수업이 끝났다.
본인 학부 기준(경북대학교 컴공), 자료구조의 진도는 여기까지였다.
그런데 알고리즘을 공부하면서, 조금 커리큘럼에 아쉬움을 느껴 우리 자료구조 강의에서는 딱 2가지의 특별한 자료구조를 더 다루고자 한다.
이번 시간에 다룰 자료구조는 집합(Set)이다.
수학을 해본 적이 있다면, 또 우리가 이전에도 몇 번 읽어볼 거리나 서로소 집합을 통해 다룬 적 있기에 익숙할 것이다.
바로 집합의 정의와 ADT에 대해 알아보자.
집합(Set)이란?
집합(Set)이란 순서, 중복 없이 원소가 집합에 속하는지 아닌지만 판단하는 자료구조이다.
그렇기에 ADT도 원소의 추가/제거/조회 이 3가지만 다루면 된다.
대부분 자료구조에서 검색/조회를 다루었기 때문에, 사실 지금까지 배웠던 대부분 자료구조로 충분히 구현할 수 있다.
하지만 그중에서도, 검색에 최적화된 자료구조인 이진 검색 트리(BST)가 있었다.
그리고 BST에서도 원소의 추가, 삭제, 조회 모든 것이 가능했다. (중복 추가는 무시하면 됨)
하지만 BST는 사실 구조체 단위로 노드도 만들어야 하고, 트리의 구현이 쉬운 것이 아니기에 더 좋은 자료구조를 찾았다.
그렇게 눈을 돌린 것은 배열이었는데, 집합의 원소를 배열 인덱스를 통해 바로 접근할 수 있다면 좋으리라 생각한다.
즉 아래와 같은 구조면 된다는 뜻이다.
2, 3, 5 원소가 집합에 속한다면 1, 아니면 0으로 표현을 하면 된다.
int set[6] = {0, 0, 1, 1, 0, 1};
그런데 이는 생각보다 쉽지 않은데 아래와 같은 문제가 있다.
-
겨우 int 정수의 표현 범위만 해도 무려 21억이다. (21억 개 원소를 가진 배열을 선언하면, stack 메모리를 초과한다.)
-
원소는 정수형 말고도 많은 자료형이 있을 수 있다.(문자열, 문자, 실수 등..)
하지만 컴퓨터 공학자들은 위 문제를 해결하는 혁신적인 방법을 만들어낸다.
그 방법인 해시 함수를 소개하겠다.
해시 함수란?
우선 수학에서 함수는 어떤 집합을 다른 집합으로 매칭시키는 개념이다.
예를 들어, y = 2x라는 함수는 {1, 2, 3, 4}라는 x 집합의 값을, {2, 4, 6, 8}이라는 y 집합의 값으로 바꿀 수 있다.
다른 함수인 y = x % 10은 x의 범위가 얼마나 넓든 간에 0 ~ 9의 집합으로 매칭시킬 수 있다.
또한, y = x * 100이라는 함수는 0.01보다 큰 모든 실수를 정수로 타입을 바꿔서 매칭할 수도 있다.
이게 왜 유의미하냐 하면, 어떤 특정 값을 다루기 쉬운 인덱스 값으로 바꿀 수 있기 때문이다.
29174923은 배열의 인덱스로 쓰기 어렵지만, \%10을 취한 3은 훨씬 다루기 쉽다.
또, 0.37은 배열의 인덱스로 쓸 수 없지만, *100을 취한 값인 37은 인덱스로 사용할 수 있다.
이뿐만이 아니다! 문자열도 문자가 정수의 값을 가지는 아스키코드라는 점을 이용하면 정수 인덱스로 만들 수 있다. (아래의 예제에서 다루겠다.)
이렇게 원래의 값을 함수를 통해 특정한 값(정수형)으로 바꾸는 작업을 해싱이라고 한다. 또, 그 함수는 해시 함수라고 한다.
원래 값을 키, 해시 함수를 통해 바뀐 값을 해시값이라고 한다.
대표적인 해시 함수는 위에서 언급한 % 연산을 이용하지만, 실제 사용되는 해시 함수는 훨씬 복잡한 수식을 사용한다.
아직은 안 익숙할 테니, 예제를 보며 이해해보자.
해싱의 예시 1
우리는 {123456780, 123456781, 123456782, 123456783, 123456784, 123456785}를 작은 인덱스로 매칭하고 싶다.
여기서 쓸만한 가장 간단한 해시 함수는 x % 10이다.
모든 원소에 대해 중복되는 해시값을 만들지 않기 때문이다.
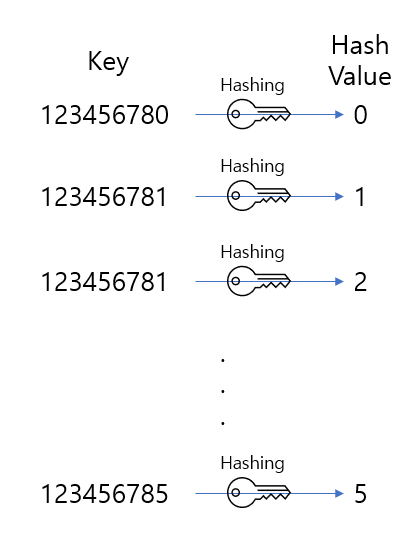
그 결과로는, 위와 같은 {0, 1, 2, 3, 4, 5} 해시값 집합을 가질 수 있다.
우리가 이렇게 한 이유를 까먹으면 안 된다.
해시값을 인덱스로 쓰고, 배열을 이용해서, 원래 원소를 저장하기 위해서였다.
그림으로 보면 아래처럼 나타난다.

깔끔하게 다루기 쉬운 인덱스로, 다루기 어려운 큰 원소를 저장했다.
이렇게 해시 함수와 배열을 이용해서, 특정 값을 고유한 인덱스로 대응하여 데이터를 저장하는 자료구조를 해시 테이블라고 한다.
같은 작업을 하나만 더 해보겠다.
해싱의 예시 2
우리는 {“banana”, “apple”, “pineapple”, “orange”}를 인덱스로 매칭하고 싶다.
여기서 쓸만한 가장 간단한 해시 함수는 각 아스키코드 다 더한 값 % 10이다.
아스키코드가 정수인 점을 이용한 것이다.
물론, 여기서는 예제를 위한 적당한 해시 함수를 가져왔을 뿐, 모든 문자열을 위 해시 함수로 처리할 수 있는 것은 아니다.
참고로 각 원소의 아스키 코드 합은 609, 530, 958, 836이고, 해시값은 9, 0, 8, 6이다.
이렇게 이번 예시에서 볼 수 있듯 원소의 순서대로 해시값을 가질 필요는 없다.
존재의 유무만 확인하면 되기 때문이다.
그럼 아래와 같은 해시 테이블 구조로 저장된다.

이제 조금 이해가 되었다면, 직접 해시 함수를 이용해서 해시 테이블을 구현해보자.
그리고 그 테이블로 ADT를 구현해서 집합 자료구조를 만들어보자.
집합 ADT
역시나 ADT는 요구에 맞게 작성되는 것이기에, 절대적인 것이 아니라 필요에 맞게 수정할 수 있다.
집합의 구현
아래 코드 예제를 보자.
#include <stdio.h>
#define NODE 6
/*
자료 : 정수
{123456780, 123456781, 123456782, 123456783, 123456784, 123456785}를
{0, 1, 2, 3, 4, 5}로 매칭
기능1 추가 : 집합에 원소를 추가한다
기능2 삭제 : 집합에서 원소를 삭제한다
기능3 조회 : 집합에 원소가 속한지 확인한다
*/
// 해시 함수
int hash(const int value) {
return value % 10;
}
//기능1 추가 : 집합에 원소를 추가한다
void insert(int set[], const int value) {
int hashValue = hash(value);
set[hashValue] = value;
printf("%d is added to the set with %d by hash function\n\n", value, hashValue);
}
//기능2 삭제 : 집합에서 원소를 삭제한다
void delete(int set[], const int value) {
int hashValue = hash(value);
if (set[hashValue] == -1) {
printf("%d is not in the set\n\n", value);
return;
}
set[hashValue] = -1;
printf("%d is deleted from the set\n\n", value);
}
//기능3 조회 : 집합에 원소가 속한지 확인한다
void search(int set[], const int value) {
int hashValue = hash(value);
if (set[hashValue] == -1) {
printf("%d is not in the set\n\n", value);
}
else {
printf("%d is in the set\n\n", value);
}
}
int main(void) {
int set[NODE] = { -1, -1, -1, -1, -1, -1 };
// 매칭되는 원소가 없다면 -1로 해놓음
insert(set, 123456780);
insert(set, 123456781);
insert(set, 123456782);
insert(set, 123456783);
insert(set, 123456784);
insert(set, 123456785);
delete(set, 123456781);
delete(set, 123456783);
delete(set, 123456785);
search(set, 123456780);
search(set, 123456781);
search(set, 123456782);
search(set, 123456783);
search(set, 123456784);
search(set, 123456785);
}
결과창
123456780 is added to the set with 0 by hash function
123456781 is added to the set with 1 by hash function
123456782 is added to the set with 2 by hash function
123456783 is added to the set with 3 by hash function
123456784 is added to the set with 4 by hash function
123456785 is added to the set with 5 by hash function
123456781 is deleted from the set
123456783 is deleted from the set
123456785 is deleted from the set
123456780 is in the set
123456781 is not in the set
123456782 is in the set
123456783 is not in the set
123456784 is in the set
123456785 is not in the set
위 해시 테이블의 한계
사실 잘 따라왔다면, 위의 예시를 보며 의문을 가져야 한다.
왜냐하면, 이런 허점이 있기 때문이다.
만약 집합의 원소 범위가 123456780에서 123456785가 아니라, 123456780에서 123456790이라면??
알다시피 123456780과 123456790은 해시값이 같다.
이렇게 두 다른 키가 같은 해시값을 가지는 경우를 충돌이라고 한다.
또한, 충돌이 없는 이상적인 함수를 퍼펙트 해시 함수(perfect hash function)이라고 한다.
하지만 퍼펙트 해시 함수는 특정한 경우 존재하고, 일반적으로는 없는 것으로 알려져 있다.
즉, 일반적인 상황에 대해서 충돌의 발생은 불가피하다.
그렇다면 어떻게 충돌을 해결할까?
다음 시간에는 충돌의 해결법에 대해 알아보자.
번외) BST를 이용한 집합 ADT 구현
우리가 어떠한 자료형의 원소든 해시 함수를 통해 정수형으로 바꿀 수 있음을 알았다.
그 말은 BST를 이용해서도 추가/제거/탐색이 가능하다는 소리이다.
아래와 같은 구조체를 이용해서 구현해보길 바란다.
struct node{
int hash_value; // 해시 값
int key;// 원래 값
}
해시 테이블을 이용하면 추가, 제거, 탐색이 편하다.
하지만 해시값이 커지면 인덱스가 커지고, 과도한 메모리가 사용될 수 있다.
그럴 때는 오히려, 시간의 번거로움을 감수하더라도 BST로 구현하는 편이 메모리를 아낄 수 있다.
또, 해시 테이블과는 다르게 BST는 노드 구조체를 아래와 같이 수정한다면
struct node{
int hash_value; // 해시 값
int key[5];// 원래 값
}
해시값당 최대 몇 개의 원소까지 중복을 허용할 수도 있다는 장점도 있다.
✅ 1. 해싱과 해시 함수를 안다.
✅ 2. 해시 테이블을 만들 수 있다.
✅ 3. 해시 테이블을 통해, 집합 ADT를 구현할 수 있다.
✅ 4. BST를 통해, 집합 ADT를 구현할 수 있다.
⚠️ 퍼펙트 해시 함수는 일반적으로 존재하지 않는다.
⚠️ 해시 함수는 성능에 지대한 영향을 준다. 신중히 결정해야 함.
💣 과제,
-
해시테이블를 이용해서 {‘banana’, ‘apple’, ‘pineapple’, ‘orange’}를 담는 집합을 구현해본다.(난이도 中) (힌트 : 강의 원문 참고)
-
BST를 이용해서 {‘banana’, ‘apple’, ‘pineapple’, ‘orange’}를 담는 집합을 구현해본다.(난이도 中) (힌트 : 강의 원문 참고)
🔜 더 공부해보기,




Comments