17 min to read
자료구조(20) - 해시 충돌 관리법
체이닝과 개방 주소법

🔚 짧게 하는 복습
✅ 1. 해싱과 해시 함수를 안다.
✅ 2. 해시 테이블을 만들 수 있다.
✅ 3. 해시 테이블을 통해, 집합 ADT를 구현할 수 있다.
✅ 4. BST를 통해, 집합 ADT를 구현할 수 있다.
혹시 기억이 안 난다면, 다시 돌아가자
저번 시간에는 해시 함수를 통해 BST나 해시 테이블을 만드는 방법을 배웠다.
강의 마지막 부분에는 중요한 화제를 다루었다.
해시 값이 같은 경우를 충돌이라고 했고, 이번 강의에서는 이 충돌을 어떻게 관리하는 지에 대해 다루기로 했다.
BST를 이용한 집합은 구조체를 수정하면 쉽게 할 수 있지만, 테이블은 아예 다른 방법을 이용한다.
그 중 가장 유명한 방법인 체이닝과 개방 주소법을 통해 해결해보겠다.
체이닝(chaining)이란?
체이닝이란 키를 저장하는 배열을 만드는 것이 아니라, 키들을 저장하는 연결리스트를 저장하는 배열을 만드는 것이다.
이해가 잘 안 되겠지만 아래 그림을 보자.
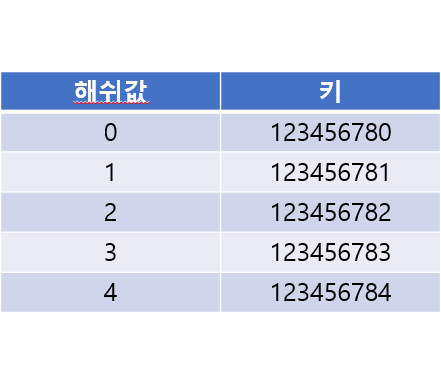
123456790의 해시값인 0 인덱스에는 이미 키가 저장되어있는 상태이다.
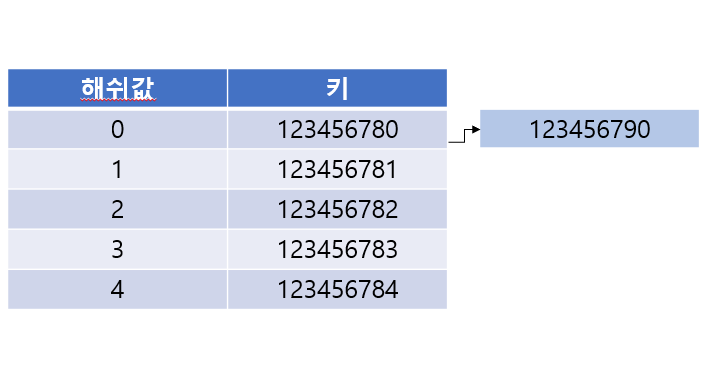
여기서 위 그림처럼 연결리스트를 통해 그 뒤에 추가로 붙이는 것이다.
체이닝을 통한 충돌 해결은 자세한 구현은, 연결리스트 배열과 다르지 않기에 과제로 남기겠다.
이렇게 해시테이블의 크기가 고정되어있지 않은 경우, 동적 해시테이블이라고 한다.
장점은 얼마나 데이터가 들어오던지 충돌을 완벽하게 해결할 수 있다.
단점은 그만큼 동적할당을 통해 메모리 소모가 심해진다.
개방 주소법(Open Addressing)이란?
개방 주소법이란 충돌이 발생하면 키를 다른 빈 곳에 저장하는 방법이다.
여기서 어떠한 규칙으로 다른 공간에 저장하느냐에 따라
- 선형 탐사(Linear Probing)
- 제곱 탐사(Quadratic Probing)
- 이중 해싱(Double Hashing)
- 무작위 탐사(Random Probing)
으로 나뉜다.
선형 탐사(Linear Probing)
만약 탐색 인덱스를 x0, x1, x2… 라고 하면, 아래와 같은 규칙을 가진다.
xi = (i + x0) % m (m은 배열의 마지막 인덱스)
쉽게 말하면, 처음 인덱스가 30인데 이미 차있다면 31, 32 … 마지막 인덱스, 0, 1 … 순서로 탐색 된다는 소리이다.
탐색하다가, 빈 곳을 찾으면 바로 그 인덱스에 키를 저장한다.
제곱 탐사(Quadratic Probing)
이중 탐사는 아래와 같은 식을 가진다.
xi = (x0 + i * k1 + i2*k2) % m (m은 배열의 마지막 인덱스, k1, k2는 임의의 상수)
선형 탐사보다는 충돌된 인덱스로부터 더 비규칙적으로 이동하기 때문에, 충돌의 확률이 적다.
하지만 엄연히 k1, k2의 값에 따라 성능이 달라진다.
만약 k1을 0, k2를 1이라고 하면 30, 31, 34, 39 .. 순서로 탐색한다는 의미이다.
이중 해시(Double Hashing)
이는 충돌이 발생 시, 아예 다른 해시 함수를 하나 더 이용해서 최종 해시값을 정하는 방식이다.
예를 들어, xi = (h0 i*h1) % m (m은 배열의 마지막 인덱스, h0, i*h1는 각각 해시값)
무작위 탐사(Random Probing)
무작위 탐사는 앞의 탐사들과 달리 증가나 감소가 아니라, 다음 인덱스를 난수로 정하는 것이다.
이는 무작위라는 특성상 성능을 보장할 수 없는 것이 특징이다.
개방 주소법의 장점은 동적으로 할당되지 않기 때문에, 메모리가 절약된다는 점이다.
하지만 단점이 명확한데, 특정 영역에서 충돌이 많이 일어나고 키의 입력이 몰릴 수 있다. 이를 클러스터링이라고 한다.
각 탐사 방법의 특징
또한, 각 탐사 방법은 아래의 특징을 가진다.
선형 탐사 (Linear Probing)
장점:
구현이 간단하며 메모리를 효율적으로 사용할 수 있다.
단점:
1차 클러스터링(Primary Clustering)이 발생할 수 있어, 충돌이 반복되면 성능이 저하될 수 있다.
데이터가 일부 영역에 몰려서 해시 테이블이 불균형해질 수 있다.
제곱 탐사(Quadratic Probing)
장점:
선형 탐사에서 발생하는 1차 클러스터링 문제를 해결한다.
충돌이 발생한 인덱스로부터 더 떨어져서 탐사하기 때문에 규칙적인 패턴이 줄어든다.
단점:
여전히 2차 클러스터링(Secondary Clustering) 문제가 발생할 수 있다.
선형 탐사보다는 연산이 복잡하게 된다.
이중 해싱(Double Hashing)
장점:
더 복잡한 해시 함수를 사용하기 때문에 클러스터링 문제를 줄일 수 있다.
두 번째 해시 함수가 충돌이 발생한 경우를 고려하기 때문에 무작위 탐사와 비슷한 성능을 가질 수 있다.
단점:
구현이 복잡하고 추가 계산이 필요하다.
나쁜 해시 함수나 나쁜 파라미터로 인해 성능이 감소할 수도 있다.
무작위 탐사(Random Probing)
장점:
완전히 무작위로 탐사하기 때문에 클러스터링의 발생 가능성이 작다.
다양한 상황에서 성능이 좋을 수 있다.
단점:
무작위성을 유지하기 위해 추가적인 난수 생성이 필요하므로 연산이 늘어날 수 있다.
구현이 복잡하며 일관된 성능을 보장하기 어려울 수 있다.
설명만 하고 넘어가긴 아쉬우니, 공개 주소법 중 선형 탐사와 이중 해싱만 직접 구현해보겠다. (나머지는 과제로 넘기겠다.)
선형 탐사(Linear Probing) 구현
#include <stdio.h>
#define NODE 6
/*
자료 : 정수
{123456780, 123456781, 123456782, 123456783, 123456784, 123456785}를
{0, 1, 2, 3, 4, 5}로 매칭
기능1 추가 : 집합에 원소를 추가한다
기능2 삭제 : 집합에서 원소를 삭제한다
기능3 조회 : 집합에 원소가 속한지 확인한다
*/
// 해시 함수
int hash(const int value) {
return value % 10;
}
//기능1 추가 : 집합에 원소를 추가한다
void insert(int set[], const int value) {
int hashValue = hash(value);
int probing_num = 0;
// 전부 탐색했는데 없으면 무한루프가 돌게되니
while(set[hashValue] != -1 && probing_num<NODE) {
hashValue += 1;
probing_num += 1;
// 선형 탐사, 탐사수 기록
if (hashValue == NODE) {
hashValue = 0;
}
//최대 인덱스가 넘어가면 0부터 다시 시작
}
if (probing_num == NODE) {
printf("Hash table is full!\n\n");
return;
}
set[hashValue] = value;
printf("%d is added to the set with %d by hash function\n\n", value, hashValue);
}
//기능2 삭제 : 집합에서 원소를 삭제한다
void delete(int set[], const int value) {
int hashValue = hash(value);
int probing_num = 0;
while(set[hashValue] != value && probing_num < NODE) {
hashValue += 1;
probing_num += 1;
// 선형 탐사, 탐사수 기록
if (hashValue == NODE) {
hashValue = 0;
}
//최대 인덱스가 넘어가면 0부터 다시 시작
}
// 루프를 나왔는데 값이 아니면 없는 것이고, 값이면 삭제한다.
if (set[hashValue] == value) {
set[hashValue] = -1;
printf("%d is deleted from the set\n\n", value);
return;
}
else {
printf("%d is not in the set\n\n", value);
return;
}
}
//기능3 조회 : 집합에 원소가 속한지 확인한다
void search(int set[], const int value) {
int hashValue = hash(value);
int probing_num = 0;
while (set[hashValue] != value && probing_num < NODE) {
hashValue += 1;
probing_num += 1;
// 선형 탐사, 탐사수 기록
if (hashValue == NODE) {
hashValue = 0;
}
//최대 인덱스가 넘어가면 0부터 다시 시작
}
// 루프를 나왔는데 값이 아니면 없는 것이고, 값이면 있는 것임.
if (set[hashValue] == value) {
printf("%d is in the set\n\n", value);
}
else {
printf("%d is not in the set\n\n", value);
}
}
int main(void) {
int set[NODE] = { -1, -1, -1, -1, -1, -1 };
// 매칭되는 원소가 없다면 -1로 해놓음
insert(set, 123456780);
insert(set, 123456781);
insert(set, 123456782);
insert(set, 123456783);
insert(set, 123456784);
insert(set, 123456790);//충돌 일으킴
insert(set, 123456785);
delete(set, 123456781);
delete(set, 123456783);
delete(set, 123456785);
search(set, 123456780);
search(set, 123456781);
search(set, 123456782);
search(set, 123456783);
search(set, 123456784);
search(set, 123456790);
search(set, 123456785);
}
결과창
123456780 is added to the set with 0 by hash function
123456781 is added to the set with 1 by hash function
123456782 is added to the set with 2 by hash function
123456783 is added to the set with 3 by hash function
123456784 is added to the set with 4 by hash function
123456790 is added to the set with 5 by hash function
Hash table is full!
123456781 is deleted from the set
123456783 is deleted from the set
123456785 is not in the set
123456780 is in the set
123456781 is not in the set
123456782 is in the set
123456783 is not in the set
123456784 is in the set
123456790 is in the set
123456785 is not in the set
이중 해싱(Double Hashing) 구현
#include <stdio.h>
#define NODE 6
/*
자료 : 정수
{123456780, 123456781, 123456782, 123456783, 123456784, 123456785}를
{0, 1, 2, 3, 4, 5}로 매칭
기능1 추가 : 집합에 원소를 추가한다
기능2 삭제 : 집합에서 원소를 삭제한다
기능3 조회 : 집합에 원소가 속한지 확인한다
*/
int hash1(const int value) {
return value * 3;
}
int hash2(const int value) {
return value * 17;
}
// 해시 함수
int hash(const int value, int i) {
return (hash1(value) + i * hash2(value)) % 5;
}
// 해시값 2개를 써서 해싱을 한다.
//기능1 추가 : 집합에 원소를 추가한다
void insert(int set[], const int value) {
int probing_num = 0;
int hashValue = hash(value, probing_num);
// 탐사 횟수를 전달해서 충돌을 관리한다.
// 전부 탐색했는데 없으면 무한루프가 돌게되니
while(set[hashValue] != -1 && probing_num<NODE) {
hashValue += 1;
probing_num += 1;
// 선형 탐사, 탐사수 기록
if (hashValue == NODE) {
hashValue = 0;
}
//최대 인덱스가 넘어가면 0부터 다시 시작
}
if (probing_num == NODE) {
printf("Hash table is full!\n\n");
return;
}
set[hashValue] = value;
printf("Collison occured for %d times\n\n", probing_num);
// 충돌을 보기 힘드니, 충돌 횟수를 시각화
printf("%d is added to the set with %d by hash function\n\n", value, hashValue);
}
//기능2 삭제 : 집합에서 원소를 삭제한다
void delete(int set[], const int value) {
int probing_num = 0;
int hashValue = hash(value, probing_num);
while(set[hashValue] != value && probing_num < NODE) {
hashValue += 1;
probing_num += 1;
// 선형 탐사, 탐사수 기록
if (hashValue == NODE) {
hashValue = 0;
}
//최대 인덱스가 넘어가면 0부터 다시 시작
}
if (set[hashValue] == value) {
set[hashValue] = -1;
printf("%d is deleted from the set\n\n", value);
return;
}
else {
printf("%d is not in the set\n\n", value);
return;
}
}
//기능3 조회 : 집합에 원소가 속한지 확인한다
void search(int set[], const int value) {
int probing_num = 0;
int hashValue = hash(value, probing_num);
while (set[hashValue] != value && probing_num < NODE) {
hashValue += 1;
probing_num += 1;
// 선형 탐사, 탐사수 기록
if (hashValue == NODE) {
hashValue = 0;
}
//최대 인덱스가 넘어가면 0부터 다시 시작
}
if (set[hashValue] == value) {
printf("%d is in the set\n\n", value);
}
else {
printf("%d is not in the set\n\n", value);
}
}
int main(void) {
int set[NODE] = { -1, -1, -1, -1, -1, -1 };
// 매칭되는 원소가 없다면 -1로 해놓음
insert(set, 123456780);
insert(set, 123456781);
insert(set, 123456782);
insert(set, 123456783);
insert(set, 123456784);
insert(set, 123456790);
insert(set, 123456785);
delete(set, 123456781);
delete(set, 123456783);
delete(set, 123456785);
search(set, 123456780);
search(set, 123456781);
search(set, 123456782);
search(set, 123456783);
search(set, 123456784);
search(set, 123456790);
search(set, 123456785);
}
결과창
Collison occured for 0 times
123456780 is added to the set with 0 by hash function
Collison occured for 0 times
123456781 is added to the set with 3 by hash function
Collison occured for 0 times
123456782 is added to the set with 1 by hash function
Collison occured for 0 times
123456783 is added to the set with 4 by hash function
Collison occured for 0 times
123456784 is added to the set with 2 by hash function
Collison occured for 5 times
123456790 is added to the set with 5 by hash function
Hash table is full!
123456781 is deleted from the set
123456783 is deleted from the set
123456785 is not in the set
123456780 is in the set
123456781 is not in the set
123456782 is in the set
123456783 is not in the set
123456784 is in the set
123456790 is in the set
123456785 is not in the set
적재율과 이상적인 해시 함수
해시 테이블의 성능을 결정하는 가장 큰 두 가지 요소는 적재율, 그리고 해시 함수이다.
적재율은 해시 테이블에서 사용 중인 공간의 정도를 나타내는 지표이다.
적재율의 공식은 (해시 테이블에 저장된 항목의 수) / (해시 테이블의 크기)이다.
일반적으로 0에서 1의 값을 가지며, 백분율로는 0~100%의 값을 가진다.
적재율이 1이 되는 순간 무조건 충돌이 일어난다는 뜻이며, 0.7 정도의 적재율이 이상적인 것으로 알려져 있다.
보통 이 이상적인 적재율을 유지하기 위해 동적 해시 테이블을 많이 사용한다.
또한, 해시 함수는 해시 테이블의 본질이라고 봐도 무방한데, 일반적으로는 아래와 같은 함수를 좋은 해시 함수라고 한다.
-
균일한 분포: 해시 테이블의 모든 위치에 대해 균일한 확률로 데이터를 분배해야 한다.
-
고유성: 서로 다른 입력에 대해 다른 해시값이 생성되어야 한다.
-
빠른 연산: 해시 함수의 계산이 빠르게 이루어져야 한다.
일반적으로 해시 함수를 우리가 골라야 하는 경우는 거의 없지만, 어느 해시 함수가 좋은 해시 함수인지는 알아둘 필요가 있다.
✅ 1. 체이닝을 통해 충돌 관리를 할 수 있다.
✅ 2. 개방 주소법의 각 탐사 방법을 안다.
✅ 3. 각 탐사 방법의 장단점을 안다.
✅ 4. 체이닝과 개방 주소법을 구현할 수 있다.
✅ 5. 적재율과 좋은 해시 함수의 조건을 안다.
💣 과제,
-
체이닝을 통한 해시 충돌 관리를 구현해본다.(난이도 中)
-
제곱 탐사를 통한 해시 충돌 관리를 구현해본다.(난이도 中)
-
무작위 탐사를 통한 해시 충돌 관리를 구현해본다.(난이도 中)




Comments