5 min to read
C 언어(4) - 자료형 더 깊게 이해하기(부동소수점)
부동소수점을 이해, 실수 자료형 심화 이해

🔚 짧게 하는 복습
✅ 1. C언어에서 정수형은 (unsigned) short int, (unsigned) int, (unsigned) long long int를 가지고 각각의 크기와 표현 범위, formatting을 알자.
✅ 2. 위의 저장공간에 이진수를 넣기 위해 고생하셨던 컴퓨터 공학자들의 노고를 기리며, 이진수의 표현 방법들과 각각의 특징을 알자.
✅ 3. 언더플로우와 오버플로우를 이해한다.
혹시 기억이 안 난다면, 다시 돌아가자
저번 시간에는 정수형을 다뤘으니, 오늘은 두 번째 실수형이다.
사실 이진수를 다루면서 우리는 이진법에서 소수를 어떻게 표현하는지도 다루었다.
그리고 또한 저번에 봤던 이 표에서
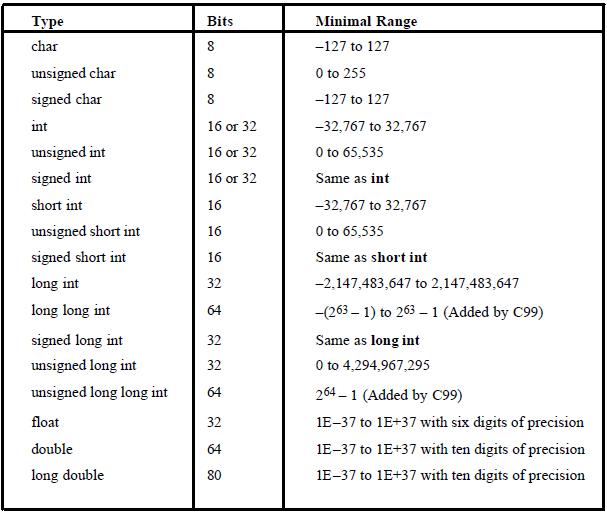
double은 64bit, float는 32bit, long double은 80bit라고 되어 있으니 대충 double은 float보다는 표현 범위가 넓고, long double은 double보다 더 넓은 범위를 표현할 것으로 추측할 수 있다.
고정소수점
우리가 저번 수업에 소수를 다루는 방법을 잘 생각해보자. 소수점 왼쪽, 오른쪽을 나누어서 이진수로 각각 표현할 수 있었다.
110.1112이면 각각 정수, 실수 부분에 3bit, 3비트씩 총 6bit를 쓰면 되는 것이다.
자 그런데 이런 상황을 가정해보자.
하나는 1111111111111111111111111111111111111111111111111.12를 저장하고,
다른 하나는 1.11111111111111111111111111111111111111111111111112을 저장해보자.
참고로 위의 숫자는 둘 다 50자리의 이진수이다.
우리가 정수를 다룰 때와 달리, 정수 부분과 실수 부분에 각각 얼마나 많은 저장공간을 할당해야 하는지가 모호해진다.
double의 64bit니까 부호 비트를 1bit 빼고, 반반 나누어서 32bit, 31비트씩 주는 것이 합리적일까?
이는 최악의 선택이다. 그 이유는 정수 부분에 큰 숫자가 들어올 수 있는데 32bit 밖에 없고, 실수 부분에 엄청 작은 숫자까지 표현해야 할 수도 있는데 32bit 즉, 2-31까지 밖에 표현할 수 없기 때문이다.
즉 이것도 저것도 할 수 없게 된다. 이렇게 정수 부분과 실수 부분에 있어 자리를 이미 나눠 놓고 저장하는 방법을 고정소수점 방법이라고 한다.
당연히 이 문제는 실제 상황에서 큰 실수를 다루는 데에 문제가 생겼고, 컴퓨터 공학자들이 새로운 방법을 만들어 낸다.
부동 소수점
우리가 매우 큰 수나 작은 수를 표기할 때, 지수로 표현을 하는 방법을 사용한다.
이 포스팅에만 해도 0.00000000002.4.65661287…. 이란 숫자 대신 2-31 썼는 것처럼.
여기서 컴퓨터 공학자들이 아이디어를 얻어서, 소수를 지수로 표현하는 방법을 선택한다.
예를 들어 0.0001010111012라는 숫자를 저장할 때, 처음부터 자리를 할당해놓고 저장하는 것이 아니라
가장 앞에 있는 1을 찾아서 1.010111012 x 2-4으로 표현을 한 후, 앞의 실수 부분의 소수점 아랫자리 숫자와 뒤의 지수를 저장하기로 한 것이다.
앞의 소수 중 소수점 아랫부분을 가수부, 뒤의 지수 부분을 지수부라고 보통 말한다.
double을 기준으로 부호 부분 1bit(이 부호 비트는 최상단 비트 혹은 MSB(Most Significant Bit)라고 한다), 지수부는 11bit 가수부는 52bit다.
가수부는 우리가 아는대로 가장 왼쪽 비트는 소수점 바로 아랫자리(2-1)이고 차례대로 오른쪽으로 2-2, 2-3… 자리이다.
그런데 지수부는 어떨까? 음수와 양수를 모두 가져야 하니 2의 보수법을 통해서 나타내면 될까?
결과부터 말하자면 아니다. 이는 컴퓨터 공학자들의 센스가 나타나는 부분인데 기본적으로 모든 비트에 0이 들어가면 정수에서는 0이다.
그런데 만약 지수부를 2의 보수법을 택하면 모든 비트에 0이 들어갔을 때 1.0 x 20 = 1.0이 돼버리기 때문이다.
편향 지수
그래서 편향 지수라는 방법을 쓰게 된다.
편향 지수란 정수 계산처럼 지수부도 2의 보수법을 통해서 -211 ~ 210-1 사이 값 중 값을 구하고, 최댓값인 -210-1을 더한 값을 말한다.
이렇게 되면 double의 지수부가 모두 0으로 채워졌을 때 ,
0…..02
= -211 + 210 -1
= -2 x 210 + 210 -1
= -210 -1로 가장 작은 값을 가지게 되고,
double의 지수부가 모두 1로 채워졌을 때 211 -2로 가장 큰 값을 가지게 된다.
이는 float와 long double도 비트 수만 다를 뿐 2의 보수법을 통해서 값을 구하고, 최댓값을 더해서 편향 지수를 만든다는 점은 같다.
순수한 0과 무한대, Nan
우리가 구한대로 지수부가 11bit인 double은 지수부에서 -210 -1 ~ 211 -2를 가져야 하지만 실제로 사용되는 범위는 최솟값과 최댓값을 빼고 -210 ~ 211 -1만 사용한다.
모든 비트가 0인 경우, 아까보다는 훨씬 작아졌지만 1.0 * -210 -1 = -210 -1로 여전히 0이 아니다.
이를 해결하기 위해 모든 비트가 0인 경우에는 언급된 일반적인 부동 소수점을 사용하지 않고, 정수 첫 자리를 0으로 만들고 지수부를 곱한다.
즉 0.가수부 x 2실수부 편향 지수 값이 되는 것이다.
이렇게 하면 순수한 0을 얻을 수 있을 뿐만 아니라 훨씬 작은 범위까지 나타낼 수 있게 되는 것이다.
또한, 모든 지수부가 1인 경우에도 특수한 경우가 생기는데
실수 계산에서 범위를 넘는 큰 혹은 작은 수나, 나누는 수가 점점 작아져 0으로 나누는 경우 2가지를 처리하는 용도로 쓰인다.
우선 모든 지수부가 1, 가수부가 모두 0이면 INF, 즉 무한대를 나타나게 되고 이는 부호 비트에 따라 음의 무한대, 양의 무한대를 둘 다 나타낼 수 있다.
또한, 모든 지수부가 1, 가수부도 모두 1이면 Nan, Not a number가 나오는데 이는 0으로 나누려고 시도하면 부호 비트를 제외한 모든 비트에 1을 채워서 Nan이 반환되도록 만들어진 것이다.
이때까지 배운 자료형들의 한계
우리는 정수형 자료와 실수형 자료가 어떻게 실제로 값이 저장되는지를 배웠다.
박스로 비유했지만, 실제로는 메모리상에 이진수의 형태로 저장이 되고
정수는 2의 보수법 혹은 이진법으로 저장이 되며, 실수는 부동 소수점을 통해서 저장된다.
둘 다 모든 문제가 해결된 것 같지만 실제로 그렇지 않다.
정수는 여전히 64bit를 벗어나는 큰 수에 대해 문제가 있으며
실수는 소수들을 정확하게 표현하지 못하는 문제가 있다., 예를 들어 가수부의 범위는 0.5 0.25 0.125…. 이다. 어떻게 해도 0.1이라는 수를 정확하게 표현할 수 없다.
우선 정수는 이유가 간단한데, 64bit를 넘는 큰 수는 실수형 계산으로 넘기면 되기 때문이다.
하지만 실수 역시 큰 수든 작은 수든 정확하게 표현하지 못하기에 여전히 한계가 있다.
그런데도 우리는 여전히 위 방식을 사용하는데, 이는 컴퓨터를 사용하는 사람이 인간이라는 이유에 있다.
64bit를 넘는 수나 엄청나게 작은 수를 다룰 때, 인간이 가지는 오차의 스케일 역시 달라지기 때문이다.
예를 들어, 만수르 씨의 자산을 매일 보여주는 프로그램을 만든다고 하자. 그의 자산을 보여주는 데 있어서 10원 아니 100만 원 단위의 오차가 의미가 있을까?
그리고 머리카락의 굵기를 재는 데 있어서 실제로 1.2919 x 10-9m라고 했을 때 1.2917 x 10-9m로 계산되면 큰 의미가 있을까?
(물론, 정밀과학에서는 아주 사소한 오차도 위험하다. 그렇기에 인간은 이 오차를 극복해 내기 위한 다른 부동 소수점 방법, 계산론, 수치해석 등을 현재도 발전시키고 있다.)
대부분의 생활에 계산을 하는 데는 위의 두 방식이 큰 문제가 없으므로, 일반적인 컴퓨터에서는 이렇게 사용이 되고 있다.
📖 오늘의 핵심(다 알기 전까지는 넘어가지 말자❗)
✅ 1. 부동 소수점 및 편향 지수에 대해 알자.
✅ 2. 지수부의 모든 비트가 0, 1일 때의 특수한 상황에 대해서 알자.
✅ 3. 왜 오차가 여전히 많은 방식을 정수든 실수든 채택하고 사용하는지 알아보자.
💣 과제, 없음.
🔜 더 공부해보기,
- 예전 컴파일러는 지금처럼 똑똑하지 못해서, 이런 오류가 나곤 했다. 읽어볼 거리1(0.1을 100번 더하면?) 읽어볼 거리2(0.1 + 0.2가 0.3일까?)
- 역시나 long double, float는 formatting이 달라지니까, formatting을 알아보자.




Comments